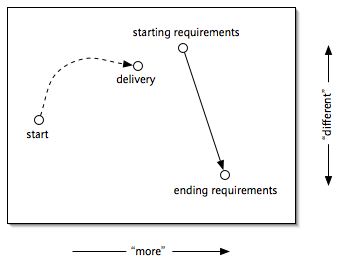
Figure 1. Big bang delivery
Software development is all about increasing the value of our products to customers. This paper presents a method of planning, tracking, and managing change to a product, and of directing change at increasing that value. It describes evolutionary planning and delivery using a Perforce-based information system. The paper is based on the author's experience of introducing Capability Maturity Model level 2 and 3 key process areas in small (less than 20 engineer) software organizations.
In this paper1 I'll tell you about the best methods I've found for managing change to a software product. The method I describe covers most of the key practices of level 2 of the Capability Maturity Model for Systems Engineering/Software Engineering [CMMI1.02].2 It's a requirements-driven process, not specialized for any particular programming method.
The goal of development is to increase the value of the product. The value is measured by the customers in the product's market. If your product is valuable enough to them they will pay you part of that value.
But our customers keep changing their minds about what's valuable. Software projects are faced with continually and rapidly changing requirements. A quality product must still meet those requirements, and it follows that a process that's going to produce a quality product must track them carefully.
To achieve the goal we must:
Understanding what is valuable is the key to the whole process. It's achieved by "requirements management" [CMMI1.02, p86].
Requirements management is how development identifies what the customer wants. The main function of requirements management is to maintain a document containing the customer requirements. This document states clearly what is desired by the customers, and should also place a value on each requirement estimating how much it is worth to the company. Here are some examples of requirements:
It's not necessary for the requirements document to be complete, provided it covers the things that are really important. The most important things to define are usually not the features, but the critical attributes. They're the things that are most difficult to track and control [Gilb88]. Start with what you know. You will quickly discover what else you need to say.
The requirements document contains our best idea of what the customer wants and values, stated in objective and measurable terms. "It works out of the box" isn't very measurable, but it can be broken down into measurable components: installation time, time to first use, ease of use, experience of first 30 minutes, etc. [Gilb88, chapter 9].
Whenever we discover something that the customer wants we add it to the requirements document. We then use the requirements to plan development.
The problem with the requirements is that they are always changing, and they usually recede into the distance, so they can never really be met. If we try to meet them all in one long delivery cycle we're bound to deliver something that is not wanted, or even deliver nothing at all until it's too late.
Attempting to meet all the requirements at once is called the big bang delivery [Gilb88, pp9-10]. The development group goes into hyperspace and hopes to come out somewhere near the desired result. The product is dismantled, and nothing works until the whole thing is done. A wasteful "code freeze" is needed to put things back together and "get it working". Furthermore, the product goes untried until near the end of the cycle, so that errors in requirements, design, or coding are not discovered until it's too late to do anything about them. It's an extremely risky strategy. Errors in requirements are most costly.
The solution to this problem is evolutionary planning and delivery [Gilb88, chapter. 7]. The idea is simple:
This is called the evolutionary delivery cycle. Take a sighting, make a step, take another sighting, another step, and so on (see figure 2). We need to keep up with the changing requirements, of course, but we are much more likely to get close to what the customer really wants, even if the customer's ideas change. The shorter we can make the cycles the better for us.3 There is less effort wasted going in the wrong direction and we deliver a more valuable product.
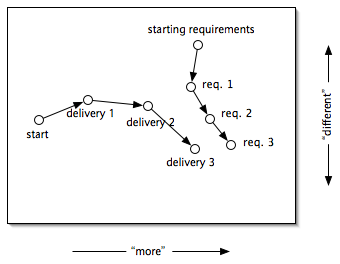
Actually, every programmer already knows about this process, because it's just like the "edit-compile-run" cycle. Programmers do some development, try out the result, modify their ideas, then do some more development, and so on. Here, we "edit" the product, "compile" it into a release, and "run" it by the customer.
The earlier we can make a release to the customer the better and more accurate our sightings will be, and therefore the higher the quality of the result. The customers are also happy because they have software which meets some of their most important requirements sooner.
Another significant benefit of this technique is that it clears up important delivery issues early. Quite often there are critically important things that get forgotten until the last minute.4 By delivering a complete product at each stage we discover these much earlier, and last minute panics are averted. Last minute work tends to be defective, and if it's something critical then that's even worse.
The disadvantage is that you have to do more analysis and planning up front, and it seems to take longer to make changes to the software that you "know" are needed. The advantage is that the final result is much closer to what's wanted, so you don't waste time on unnecessary changes or reworking it because you find out you didn't know after all. In my experience the advantages outweigh the disadvantages by a significant margin. The trouble is that you experience the disadvantages first.
Once we have some requirements, the next step is to look at the current status of the software and compare it to the requirements. If you don't know the current status then it's both urgent and important that you develop ways of measuring how well you're meeting the critical requirements; you might be able to develop tests that do this, but some subjective measurements may also be needed.
There are bound to be differences between the status and the requirements. Resources are limited and you can't hope to meet all the requirements at once. Pick out the most valuable requirements that you don't meet at the moment. Give highest priority to the requirements that present the biggest risk of failure [Gilb88, chapter 6].
Here's a practical example. A customer requires that the software runs on a new platform. This requirement needs some refinement: are all the features and all the performance required on the new platform? Which are most valuable to the customer? If you could only deliver one or two features on the platform which ones would they be? Put those first.
Get these high priority requirements analyzed so that you have some idea of the amount of effort required to meet them. Take every opportunity you can to divide them down into more manageable (smaller) pieces of work, and put the most effective pieces first.
You are now in a position to plan the next few versions of the product using version planning, a method of "project planning" [CMMI1.02, p97].
A version is a point in the evolution of the specification of the product. A version is a fixed subset of the requirements that you actually intend to meet, and meet with a schedule. You can think of a version as a snapshot of the ever-changing requirements.
The next version of the product should meet the high priority requirements that you selected earlier. The version after that should meet the next few, and so on. You should be able to work out when you can deliver the versions of the product because you have estimates of the work required. Keep the next version within easy reach, and make the date of the next version as close as you can. If there's work that seems too large to fit, or is too large to estimate, break it down. This may mean changing the design of the product, or choosing a longer path to eventual full implementation. It's worth doing that to make sure that the product is delivered and to cope with changes of plan. It'll also force you to use flexible and open-ended designs which will allow the project to adapt.5
It's only worth planning two or three versions ahead at this level of detail, because the requirements will change and you'll have to do it again at the next version. You should make rough plans further into the future, but detailed plans that far out would be wasted effort.
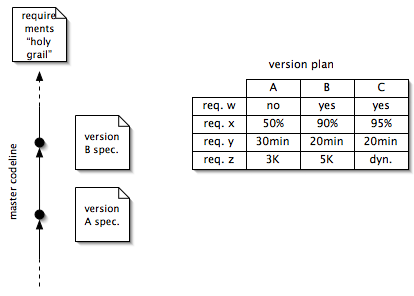
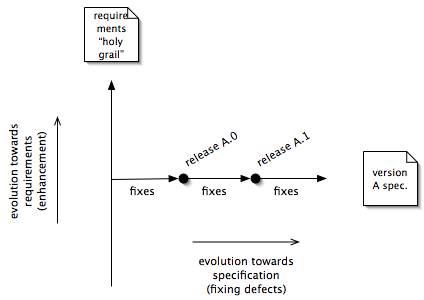
Specify each version against the critical requirements. This can be as simple as a table showing which attributes you intend to affect and how much (see figure 3).
The task is now to control change to the software to evolve it towards the next version specification, increasing the value of the product. While you're getting there, gather requirements and plan the next cycle, and so on for the lifetime of the product. It's important not to think about starts and finishes, only about continuous evolution and improvement of the product.
This is where we really get into change management. Figure 2 shows how each development cycle takes the product closer to the customer requirements, increasing its value and quality. Figure 3 shows the same thing in a different way, with the master codeline of the product constantly evolving towards the customer requirements.
The key concept of this change management process is continuous improvement. Always, always approach the requirements. Never, ever allow a change that takes you further away. This means never allowing a change that dismantles a feature, or breaks a piece of code, even "temporarily". The master codeline must always be improving. In practical terms, this means keeping the master codeline ready to build and release to customers at any time, knowing that it will be more valuable to them than before. Figure 4 is a diagram I like to draw to illustrate this simple idea. This is what "configuration management" is all about [CMMI1.02, p182].
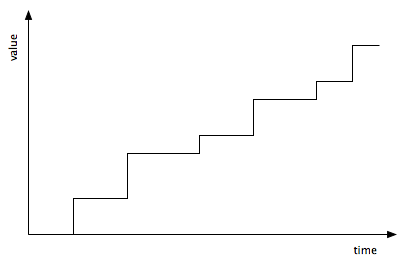
This makes it easy to meet delivery dates. You can always deliver. The only variation is in exactly what you deliver, and not in when you deliver it. The software from the master codeline is always ready to release. If you've been careful to focus efforts on the critical requirements, to employ flexible design, and to break the work down into small pieces, then you'll always be increasing the value of the product as much as possible by the time of the next delivery.
Most of the rest of this document explains how to achieve this happy state of affairs.
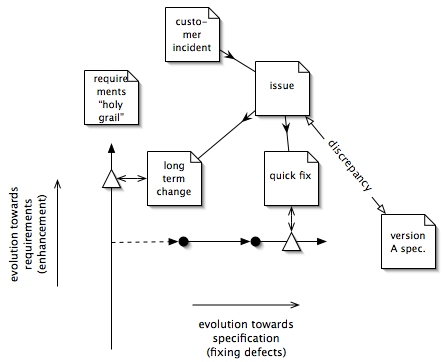
Two types of document are used to track and control change: issues and changes.
An issue is a document that reports that the product doesn't do what the customer wants. This is either because it doesn't meet its specification (a defect) or because the specification doesn't say what the customer wants (an enhancement, or new requirement). There isn't a lot of difference as far as the customer is concerned: the product doesn't do what they want, and they'd like that changed. The process described in this document treats "new development" and "bug fixing" in the same way. Issues are created whenever someone has a problem with the product. Issues subsume bug reports and enhancement requests.
Issues are the only stimulus for change. If change doesn't improve the product for the customer, there's no point in making it. Even enhancements to infrastructure must eventually increase value.
Issues are examined by management to decide if they're worth pursuing. Defect issues are scheduled depending on their impact. Enhancement issues may result in new requirements (changing the requirements document).
If they're worth pursuing they are analyzed. The problem is carefully understood and reproduced.6 Various solutions are proposed and maybe prototyped, with estimates of effort required. The issue is then examined again by management, to decide whether to make changes. One or more of the solutions are put into effect by creating changes.
A change document gives instructions to modify the product, and records exactly what was done. It also allows the work to be double-checked to make sure that it actually solves the problem and is a genuine improvement to the product. The change is not allowed into the product until it has been checked. This is achieved by making the change on a branch and only allowing it to be merged after checking (see figure 5).
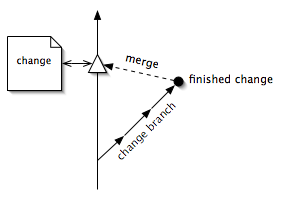
Change checking is a vital step to maintaining product integrity, and therefore to configuration management. Checking is how the senior engineers can ensure that the change fits into the overall design strategy. It's an excellent place to insert verification steps such as "peer review".7 (Verification is a key process area of CMM level 3 [CMMI1.02, p267].) It's also a stage in which software quality assurance can check that the change complies with the group's best practices.
When a customer finds a defect in the product they want a fix as soon as possible. Technical support policy may be to give the customer a fix or workaround within a few days. The "quick fix" solution to a problem is often not the right solution for the product in the long term. Quick fixes often need to go in without a great deal of thought for consistency with the overall product direction. It's important to separate these fixes from the proper solutions to problems, so that the product doesn't degrade into a pile of hacks.
We can quickly resolve a customer's problem by patching the release that they already have. This means making the smallest and quickest change that will fix their problem. This is better than trying to ship them something built from the latest master sources because that may have changed in other ways which will cause the customer problems. Shipping the latest master sources is also risky. They might contain changes that are incompatible with the customer's environment. They also don't have a known specification (so you can't tell the customer what they're getting) and can't easily be maintained later. They probably haven't been thoroughly tested since the last version. Patching a stable release gives quicker and higher quality results. This is the main motivation for version branches (see figure 6).
A version branch is created by taking a source control branch of the master sources when they are believed to meet the version specification. (Or, sometimes, when the deadline has been reached and something has to go out even if it doesn't quite meet the specification.) The sources on the version branch are called version sources. Releases of a version of a product are created from labeled version sources (see figure 6).
Releases of the product are only ever made from the sources on the version branch. Source control labels are used to mark the sources from which a release was made, so that it can be reproduced. In addition, the product image (the thing distributed to the customers) is also archived.
Releases never change. The exact content of a release is committed at the point at which the source control label for that release is created. Any problems with the release must be solved in the next release.
Not all releases go to customers. Releases can be created for internal use, as a way of assessing what the quality of the product would be. This is especially true of the first release on the version branch, in which testing sometimes reveals defects that will need to be patched on the version branch.
Only changes that fix defects are done on the version branch. A defect is where a release of the product doesn't meet its version's specification. This definition includes most things that are commonly called "bugs",9 most of which cause the product to fail to carry out one of its functions. In some sense, the version branch evolves towards its specification in the same way that the master sources evolve towards the requirements (see figure 7).
Most importantly, the version sources are a known quantity. Products built from them have been thoroughly tested and released, and so minor changes should produce predictable results. For this reason, it's important that they aren't changed very much, and any fixes done should be as small as possible to solve the specific problem that the customer has. The aim is to get the problem fixed quickly, but without introducing other problems.
Of course, if a defect is found in a version it probably also exists in the master sources as well, and needs to be fixed there too (see figure 6). The fix that is done in the master sources should be a more carefully planned change. Mainly, it needs to be a maintainable change, properly documented, and respecting the architecture of the product. This change has to last indefinitely, whereas the change to the version branch only has to last until the customer upgrades to the next version.
This apparent duplication of effort shouldn't be seen as a waste but as an opportunity. Most of the work should be done in the analysis of the issue to work out what should be done. A bandage is then applied to the version sources to fix the problem, while a complete cure is effected to the masters. A "quick fix" might be to describe a workaround to the customer.
Once a release is built it needs to be tested. The purpose of this testing is to compare the product to its specification so that management can decide whether it's suitable for general release, and to provide feedback for planning as part of "project monitoring and control" [CMMI1.02, p124].
Acceptance testing is driven by version specifications. The version specification says exactly what the product is supposed to be like (unlike the requirements) and the release should match. Acceptance test development can begin as soon as the version is planned, in parallel with product development.
Regression testing is driven by issues. Each issue is covered by a regression test, and possibly more than one. There can be a many-to-many relationship between tests and issues, as long as the relationship is clear. Regression test development can be fed from the issue process, in parallel with solution development.
It's also useful to focus testing on the areas of the software which have changed. Regression and acceptance testing can be focused on the areas of recent change by studying the change documents.
The results of testing can be tabulated against the requirements and issues and directly compared with the version plan table (see figure 3), giving a clear idea of the release quality and value. This makes it easy for a senior manager to make an informed decision about making the release generally available.
Defects (differences between the release and its version's specification) are submitted as issues. These can be patched up quickly using the method described in section 9, since we have already created a version branch, and general release is never delayed very long.
I have implemented this process in about 12 months in a team of about 20 developers, starting from a situation with no planning or source control. In a new organization it's possible to implement the process as you go, provided that your staff have a good understanding of its principles.
This is exactly what we have done at Ravenbrook Limited. This section describes how the process is implemented at Ravenbrook. Ravenbrook has completed a commercial project for Perforce Software using this process, and Perforce kindly agreed that we could make it available as an open example. The Perforce Defect Tracking Integration (P4DTI) project is visible at <URL: http://www.ravenbrook.com/project/p4dti/>. It is a complete, commercial, real, and fully documented project, including mistakes and their corrections. It has not been cleaned up for presentation. Here you can see the reality of implementation of the process.
It is important to realize that there are many ways to implement the model described in this paper. I have implemented it three different ways in three different organizations in the past ten years. Various kinds of databases can be used. The amount of formality and enforcement can also be varied according to the level of process awareness of staff and size of project.
At Ravenbrook we set up an "information server" running FreeBSD, Apache, and Perforce, with Apache configured to serve the entire contents of the Perforce repository. I used the fact that Perforce filespecs resemble URLs to make them interchangeable (our depot is called "info.ravenbrook.com", not "depot", as is usual for Perforce repositories). This makes it extremely easy for people to share information. All the business e-mail at the company is archived, with each message at a unique URL. All documents — requirements, plans, versions, releases, issues, changes, designs, procedures, tests, proposals, meeting minutes, and source code files — are stored and indexed in Perforce (usually in HTML) so that they can be referenced using URLs. I especially encourage cross-referencing from code to requirements, designs, changes, issues, and e-mail threads.
The document names are chosen carefully so that cross-references don't break. The scheme is similar to that described in Tim Berners-Lee's paper "Cool URIs don't change" [TBL98].
Everyone uses a "handbook" of procedures when working [RB98a], and these procedures are maintained and refined as we learn more about what's effective. We use the version planning, issues, and changes to modify this too.
Project requirements are maintained in a requirements document, which contains a large table. Each requirement is given a unique number, which is not reused, so that the requirements are always correctly referenced from any other document, old or new. Small corrections may be made to a requirement, but if it is changed then a new number is assigned.
The P4DTI requirements can be seen at <URL: http://www.ravenbrook.com/project/p4dti/req/>. Several requirements became obsolete during the project. These were marked, but not deleted from the document, because they are still referenced. Requirements justify design decisions made in the project, and must always be present to explain those decisions. Other requirements were split into several pieces. The original requirement remains, but the new detailed requirements have been given new numbers. In a larger project than the P4DTI I would consider some kind of database for managing requirements, but keep the basic method the same.
The master sources for a project are kept in the Perforce repository at "//info.ravenbrook.com/project/P/master/...", where P is the project name. The master sources include:
You can see the current master sources of the P4DTI project at <URL: http://www.ravenbrook.com/project/p4dti/master/>.
The master or version sources are branched for development as "//info.ravenbrook.com/project/P/branch/YYYY-MM-DD/T/...", where P is the project, YYYY-MM-DD is the date the branch was created, and T is an arbitrary mnemonic title for the branch. One or more people work on the change there. This scheme allows them to work together and submit modifications frequently8 on their private branch in order to record their progress.
The P4DTI project branches are visible at <URL: http://www.ravenbrook.com/project/p4dti/branch/>. We also maintain a list of branches and their status here.
The entire tree is branched to "//info.ravenbrook.com/project/P/version/V/..." to create a version branch, where V is the version name. Version names could use any convention. At Ravenbrook we usually use two numbers. The first is the major version number. Changing this indicates a major change in the status of the product, such as an incompatible rewrite. The minor version changes when compatible enhancements are made. For example, we go from "0.x" to "1.0" when we release the product to the public. This can be viewed as adding a "public support feature" to the specification. We go from "1.0" to "1.1" when we add something to the product. In other organizations I have used internal version code names which were not closely related to the version numbers that appeared on the final product.
The P4DTI project versions are visible at <URL: http://www.ravenbrook.com/project/p4dti/version/>.
Releases are built from fixed points along the version branch. In Perforce, we simply use the changelist number to record the point from which a release was built. The product image goes in "//info.ravenbrook.com/project/P/release/R/...", where R is the release name. The release name could follow any convention. At Ravenbrook we use the version number, followed by a number to indicate the release level. For example, "1.1.3" is a release of version "1.1". A higher numbered release fixes defects found in earlier releases, but does not usually enhance the product.
The P4DTI project releases are visible at <URL: http://www.ravenbrook.com/project/p4dti/release/>. The procedure for creating a release is at <URL: http://www.ravenbrook.com/project/p4dti/master/procedure/release-build/>. It is important to realize that this procedure evolves with the product, so the procedure for creating a release from version 1.1, for example, is actually at <URL: http://www.ravenbrook.com/project/p4dti/version/1.1/procedure/release-build/>.
We use the Perforce jobs system to store issues, and the Perforce "fixes" system to connect the issues to the changes which affect them. Perforce can then tell us which changes have been made in a release, and on top of this we have built some tools which generate release notes explaining what has changed in a release, as well as other tools for reporting the which defects exist in the various product versions.
The P4DTI project issues can be seen at <URL: http://www.ravenbrook.com/project/p4dti/issue/>. We have built various kinds of queries, including a query of the known issues for each release.
The system we use at Ravenbrook is quite simple, and has few tools, and few systems for enforcing the process. This is possible because Ravenbrook's staff have a high level of process awareness. In my experience, organizations trying to reach process maturity from a more chaotic situation need more tools, training, process documentation, and enforcement. The most important of these is training. There is no substitute for having your staff understand and appreciate the process, because then they will vary it intelligently and help to make constant improvements.
In this paper, I've described the best methods I've found for managing software product development, and how these relate to the Capability Maturity Model for Systems Engineering/Software Engineering [CMMI1.02].
There's a lot I haven't said about how this method affects the software design and its impact on the working environment and developer attitudes. There are also a lot of small lessons that we've learned and incorporated into our process handbooks. Most of these are specific to our organization and the problems of our software.
The most important thing is that the organization is learning by using an information system and a defined software process that can change and evolve just like the software itself. The process, like the product, is never finished until it is dead, and its successors have moved on.
| [CMMI1.02] | "CMMISM for Systems Engineering/Software Engineering, Version 1.02 (CMMI-SE/SW, V1.02) (Staged Representation)"; CMMI Product Development Team; Software Engineering Institute, Carnegie Mellon University <URL: http://www.sei.cmu.edu/>; 2000-11; CMU/SEI-2000-TR-018, ESC-TR-2000-018; <URL: http://www.sei.cmu.edu/pub/documents/00.reports/pdf/00tr018.pdf>. |
| [Gilb88] | "Principles of Software Engineering Management"; Tom Gilb; Addison-Wesley; 1988; ISBN 0-201-19246-2. |
| [Gilb95] | "Software Inspection"; Tom Gilb, Dorothy Graham; Addison-Wesley; 1995; ISBN 0-201-63181-4. |
| [RB98a] | "Change Management Handbook"; Richard Brooksby; Geodesic Systems; 1998-02-17. |
| [RB98b] | "Achieving Quality through Change Management"; Richard Brooksby; Geodesic Systems; 1998-07-03. |
| [TBL98] | "Cool URIs don't change"; Tim Berners-Lee; 1998; <URL: http://www.w3.org/Provider/Style/URI>. |
| 1999-05-24 | RB | Translated to HTML using AppleWorks HTML Filter 2.0. Hand edited and checked with BBEdit 5.0. |
| 1999-05-25 | RB | Corrected spelling of "peer review" and added footnote reference to [Gilb95]. |
| 1999-05-26 | RB | Updated after comments from Perforce Software staff. |
| 1999-09-20 | RB | Added copyright and copying license. |
| 2000-03-20 | RB | Converted to XHTML 1.0. |
| 2000-11-14 | RB | Corrected XHTML 1.0 syntax using BBEdit 6.0's checker. |
| 2001-08-22 | RB | Revised for Japanese translation by TOYO Corporation. Updated references to organization from Geodesic Systems to Ravenbrook Limited. Substantially expanded implementation section, adding references to P4DTI project to provide real examples of process implementation. Removed CSS due to poor support from browsers after several years. Updated licence. Made document history visible within the document. |
| 2002-11-05 | RB | Converted GIF images to PNG. Moved copyright and licence into an appendix, in line with other Ravenbrook documents. |
| 2002-12-12 | RB | Rebuilt diagrams using OmniGraffle. |
| 2003-07-09 | RB | Updated to use external common Ravenbrook white paper stylesheet. |
Copyright © 1999-2002 Richard Brooksby. This document is provided "as is", without any express or implied warranty. In no event will the authors be held liable for any damages arising from the use of this document. You may make and distribute verbatim copies of this document provided that you do not charge a fee for this document or for its distribution.
1 This paper is based on a Geodesic Systems internal document [RB98b].
2 This document does not cover "supplier agreement management" or "measurement and analysis", though the method does readily support the latter.
3 The ~100kloc projects I've managed did well on a two month cycle.
4 Like the user manual.
5 Tom Gilb discusses open-ended designs for management information systems [Gilb88]. The key idea is to choose designs that are easy to change and extend in ways that you haven't anticipated.
6 For an enhancement, "reproducing" the problem means simulating the need for the new feature or behaviour.
7 I recommend software inspections [Gilb95] as a powerful form of review.
8 I encourage developers to submit every time they make a coherent group of edits, giving them and their colleagues a chance to document the reasoning behind their work along with the edits. Usually I say that they should be checking in about every 20 minutes.
9 There are two reasons I don't like to use the word "bug". Firstly, "defect" is a better technical term for a discrepancy between product behaviour and specification. Secondly, a "bug" sounds like some sort of external influence on the software, like a cosmic ray, but is usually someone's mistake which needs to be understood, corrected, and prevented, not merely "swatted".
$Id: //info.ravenbrook.com/doc/1999/05/20/pqtcm/index.html#5 $