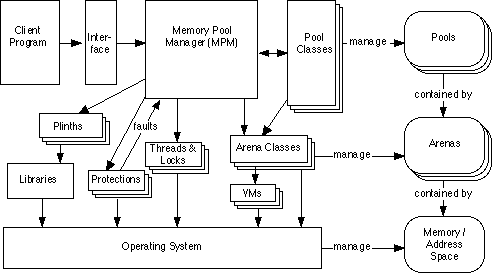
Figure 1. The MPS architecture
The Memory Pool System (MPS) is a very general, adaptable, flexible, reliable, and efficient memory management system. It permits the flexible combination of memory management techniques, supporting manual and automatic memory management, in-line allocation, finalization, weakness, and multiple simultaneous co-operating incremental generational garbage collections. It also includes a library of memory pool classes implementing specialized memory management policies.
Between 1994 and 2001, Harlequin (now part of Global Graphics) invested about thirty person-years of effort developing the MPS. The system contained many innovative techniques and abstractions which were kept secret. In 1997 Richard Brooksby, the manager and chief architect of the project, and Nicholas Barnes, a senior developer, left Harlequin to form their own consultancy company, Ravenbrook, and in 2001, Ravenbrook acquired the MPS technology from Global Graphics. We are happy to announce that we are publishing the source code and documentation under an open source licence. This paper gives an overview of the system.
The Memory Pool System (MPS) is a flexible, extensible, portable, and robust memory management system, now available under an open source licence from Ravenbrook. This paper gives an overview of the MPS, with particular emphasis on innovative things that it does.
Our goals in going open source are that as many people as possible benefit from the hard work that the members of the (now defunct) Memory Management Group put in to the MPS design and implementation. We also hope to develop the MPS further, through commercial licensing and consultancy.
The original Memory Management Group, set up in 1994, consisted of Richard Brooksby and P. Tucker Withington. Richard had previously worked in the ML Group and implemented the MLWorks memory manager and garbage collector. Tucker joined from the ailing Symbolics Inc, where he maintained the Lisp Machine's memory systems.
The initial brief of the group was to provide a memory manager for Harlequin's new Dylan system. Harlequin was also interested in a broader set of memory management products, and in absorbing the memory managers of other products, such as ScriptWorks™ (the high-end PostScript® language compatible raster image processor), LispWorks™, and MLWorks™. Initial prototyping and design work concentrated on a flexible memory management framework which would meet Dylan's requirements but also be adaptable to other projects, and form a stand-alone product.
Richard's concerns about the subtlety of a generic memory management interface, the pain of debugging memory managers, and the complexity of the Dylan implementation, led him to push for a fairly formal requirements specification. This set the tone for the group's operations, and led to extensive use of formal software engineering techniques such as inspections. At its height, the group was operating a Capability Maturity Model level 3 process [CMMI1.02]. As a result, the MPS was very robust and had a very low defect rate. This enabled the group to concentrate on development.
The Memory Management Group collaborated with the Laboratory for the Foundations of Computer Science at Edinburgh University, with the goal of formally verifying some of the algorithms [Goguen 1999].
The MPS was incorporated into the run-time system of Harlequin's DylanWorks™ compiler and development environment (now available as Functional Developer from Functional Objects). Later, it replaced the highly optimized memory manager in Harlequin's ScriptWorks™, improving performance and reliability to this day as part of Global Graphics' Harlequin RIP®.
The MPS had a fairly large and complex set of requirements from the beginning. The Harlequin Dylan project was formed from highly experienced Lisp system developers who knew was they wanted [RB 1996-10-02a]. The requirements of ScriptWorks were even more complex [RB 1995-11-01]. On top of this, we were always striving to anticipate future requirements.
This section describes the overall architectural requirements that guided all aspects of the design [RB 1997-01-28]:
The MPS consists of three main parts:
See figure 1, "The MPS architecture".
Each pool class may be instantiated zero or more times, creating a pool. A pool contains memory allocated for the client program. The memory is managed according to the memory management policy implemented by its pool class. For example, a pool class may implement a type of garbage collection, or manage a particular kind of object efficiently. Each pool can be instantiated with different parameters, creating variations on the policy.
The arena classes implement large-scale memory layout. Pools allocate tracts of memory from the arena in which they manage client data. Some arena classes use virtual memory techniques to give control over the addresses of objects, in order to make mapping from objects to other information very efficient (critically, whether an object is not white). Other arena classes work in real memory machines, such as printers.
The MPM co-ordinates the activities of the pools, interfaces with the client, and provides abstractions on which the memory management policies in the pools are implemented.
This architecture gives the MPS flexibility, its primary requirement, by allowing an application of the memory manager to combine specialized behaviour implemented by pool classes in flexible configurations. It also contributes to adaptability because pool classes are less effort to implement than a complete new memory manager for each new application. Reliability is enhanced by the fact that the MPM code can be mature code even in new applications. However, efficiency is reduced by the extra layer of the MPM between the client code and the memory management policy. This problem is alleviated by careful critical path analysis and optimization of the MPM, and by providing abstractions that allow the MPM to cache critical information.
Figure 1. The MPS architecture
The MPS is about 62Kloc of extremely portable ISO standard C [ANSI/ISO 9899:1990]. Except for a few well-defined interface modules, it is freestanding (doesn't depend on external libraries4). We have been known to port to a new operating system in less than an hour.
The code is written to strict standards. It is heavily asserted, with checks on important and subtle invariants. Every data structure has a run-time type signature, and associated consistency checking routines which are called frequently when the MPS is compiled in "cool" mode2. Much of the code has been put through formal code inspection (at 10 lines/minute or slower) by between four and six experienced memory management developers [Gilb 1995]. It was developed by a team working at approximately Capability Maturity Model level 3 [CMMI1.02]. As a result, it is extremely robust, and has a very low defect rate.
The MPS is designed to work efficiently with threads, but is not currently multi-threaded. Fast allocation is achieved by a non-locking in-line allocation mechanism (see section 5.2, "Efficient in-line allocation).
The most important feature of the MPS is the ability to combine memory management policies efficiently. In particular, multiple instances of differing garbage collection techniques can be combined. In the Harlequin Dylan system, for example, a mostly-copying main pool was combined with a mark-sweep pool for handling weak key hash-tables, a manually-managed pool containing guardians implementing user-level weakness and finalization, and a mark-sweep pool for leaf objects. The same codebase is used with a very different configuration of pools in the Harlequin® RIP1.
An overview of the abstractions that allow flexible combination can be found in section 6, "The Tracer".
The MPS achieves high-speed multi-threaded allocation using the abstraction of allocation points backed by allocation buffers [RB 1996-09-02]. The allocation point protocol also allows garbage collection to take place without explicit synchronization with the mutator threads.
An allocation point (AP) consists of three words: init, alloc, and limit. Before allocation, init is equal to alloc. The thread owning the AP reserves a block by increasing alloc by the size of the object. If the result exceeds limit, it calls the MPS, but otherwise it can initialize the object at init. Once the object is initialized, the thread commits it, by setting init equal to alloc, checking to see if limit is zero, and calling the MPS if it is. At this point the MPS may return a flag indicating that the object has been invalidated, and must be allocated and initialized again. Both the reserve and commit operations take very few instructions, and can be inlined.
The exact implementation of the AP protocol depends on the pool from which the thread is allocating. Some pools may guarantee that an object is never invalidated, for example, and so the commit check can be omitted. Most pools implement APs by backing them with allocation buffers, fairly large contiguous blocks of memory from which they can allocate without ever calling the MPS.
The AP protocol allows in-line allocation of formatted objects containing references that need tracing by a garbage collection. The MPS knows that objects up to init have been initialized and can therefore be scanned. It also knows that an object that is half-allocated (somewhere between reserve and commit) when a flip occurs (see section 6.7.3, "Phase 3: Flip") can't be scanned, and may therefore contain bad pointers, that is, pointers which have not been fixed (see section 6.5, "Scanning and Fixing"). Hence the commit check, and the re-allocation protocol. The chances of a flip occurring between a reserve and commit are very low, and re-allocation rarely happens in practice.
The AP protocol relies on atomic ordered access to words in memory, and some care must be taken to prevent some processors from re-ordering memory accesses.
A very simple pool class which only supports in-line allocation. This is useful when objects need to be allocated rapidly then deleted together (by destroying the pool). Allocation is very fast. This pool is not currently in the open sources.
The most complex and well-developed pool class, this was originally designed as the main pool for Harlequin's implementation of Dylan, but is a general purpose moving pool. It implements a generational mostly-copying algorithm [Bartlett 1989].
This is the general-purpose non-moving counterpart of AMC.
A specialized pool originally designed to supporting weak key hash tables in Dylan. In a weak key hash table, the value is nulled out when the key dies. The pool implements mark sweep collection on its contents.
This pool stores leaf objects, which do not contain references. It was originally designed for use with the Dylan foreign function interface (FFI), guaranteeing that the objects will not be protected by the MPS.
A simple pool which allocates objects of fixed (regular) small (much less than a page) size (though each instance of the pool can hold a different size). Not garbage collected.
This pool is used internally in the MPS to implement user-level finalization of objects in other pools. Some techniques from [Dybvig 1993] were used in its design.
A manually managed pool for variable sized objects. This is the pool class used internally by the MPS as the control pool for many MPS data structures. It is designed to be very robust, and, like many other MPS pools, keeps all of its data structures away from the objects it manages. It's first fit, with the usual eager coalescing.
A more sophisticated manually managed pool for variable sized objects, using bitmaps and crossing maps, designed to perform.
A general purpose manually managed pool for variable sized objects, implementing address-ordered first-fit, but with in-line worst-fit allocation. It is optimized for high performance when there is frequent deallocation in various patterns.
Some data structures and algorithms use the address of an object. This can be a problem if the memory manager moves objects around. The MPS provides an abstraction called location dependency (LD) which allows client code to depend on the locations of moving objects.
[Formats in pools.]
The Tracer co-ordinates the garbage collection of memory pools.
The Tracer is designed to drive multiple simultaneous garbage collection processes, known as traces, and therefore allows several garbage collections to be running simultaneously on the same heap. Each trace is concerned with refining a reference partition using a five-phase garbage collection algorithm that allows for incremental generational non-moving write-barrier type collection (possibly with ambiguous references) combined with incremental generational moving read-barrier type collection, while simultaneously maintaining remembered sets. Furthermore, the Tracer co-ordinates garbage collection between pools. A trace can include any set of pools. The Tracer knows nothing of the details of the objects allocated in the pools.
This section describes the abstractions used to design such a general system. The definitions are rather abstract and mathematical, but lead to some very practical bit twiddling. The current MPS implementation doesn't make full use of these abstractions. Nonetheless, they were critical in ensuring the that the MPS algorithms were correct. It is our hope that they will be of great use to future designers of garbage collection algorithms.
A reference partition is a "colouring" of the nodes in a directed graph of objects. Every object is either "black", "grey", or "white" in any reference partition. A partition (B, G, W) of a directed graph is a reference partition if and only if there are no nodes in B which have a reference to any node in W, i.e., nothing black can refer to anything white. This is a restatement of the familiar "tri-colour marking" [Dijkstra 1976].
A partition is initial if and only if there are no black nodes -- (0, G, W). All initial partitions are trivially reference partitions.
A partition is final if and only if there are no grey nodes -- (B, 0, W).
If P is a predicate, we say some reference partition (B, G, W) is a reference partition with respect to P if and only if everything with P is in W.
If we can determine a final reference partition such that the client process roots are contained in B then W is unreachable by the mutator, cannot affect future computation, and can be reclaimed.
Tracing is a way of finding final reference partitions by refinement. We start out by defining an initial reference partition with respect to a "condemned" property, such as being a member of a generation. We then perform a series of operations that preserve the reference partition invariant by moving objects reachable from the client process roots out of W in order to move objects from G to B until we end up with a final reference partition.
The key observation here is that any number of partitions can exist for a graph, and so there's no theoretical reason that multiple garbage collections can't happen simultaneously.
A second important observation is that because reference partitions can be defined for any property, one could have, for example, a reference partition with respect to a certain size of objects. The MPS uses the reference partition abstraction to implement something equivalent to "remembered sets" [Ungar 1984] by maintaining reference partitions with respect to areas of address space called zones. This is described further in section 6.2, "Induced graphs".
Reference partitions can be usefully combined. If P and Q are reference partitions, then we can define reference partitions P&cupQ as (BP∩BQ, (GP∪GQ) − (WP∪WQ), WP∪WQ) and P&capQ as (BP∪BQ, (GP&cupGQ) − (BP∪BQ), WP∩WQ).
Given a directed graph and an equivalence relation on the nodes we can define an equivalence-class induced graph whose nodes are the equivalence classes. If there's an edge between two nodes in the graph, then there's an edge between the equivalence classes in the induced graph. We can define reference partitions on the induced graph, and do refinement on those partitions in just the same way as for the original graph. We can garbage collect the induced graph.
In fact, you can think of conventional garbage collectors as doing this all the time. Imagine a graph of object fields rather than whole objects. Each object has implicit references between fields, depending on the object. The graph of objects we normally discuss is induced by the equivalence relation of being a member of the same object. Theoretically we could garbage collect individual fields by tracing this lower level graph, and reclaim the memory occupied by parts of objects! The MPM is general enough to support this, though we have not implemented a pool class which does it.
Given a directed graph G and two equivalence relations R and S, we can define a double equivalence-class induced graph. If there's a edge between two nodes x and y in the graph, then there's an edge between the equivalence class containing x under R and the equivalence class containing y under S.
The MPS divides address space into large areas called zones. The set of zones is called Z. The number of zones is equal to the number of bits in the target machine word, so a set of zones (subset of Z) can be represented by a word. Given a set of objects S, the set of edges emerging from S in the double equivalence-class induced graph induced by S and Z is called a summary. Roughly speaking, it summarizes the set of zones to which S refers. This is a BIBOP technique adapted from the Lisp Machine's hardware assisted garbage collection [Moon 1984-08].
The Tracer groups objects into segments, and maintains a summary for each segment. By doing this, it is maintaining a reference partition with respect to each zone. Segments which don't have a zone in their summary are "black" for that zone, segments which do are "grey" if they aren't in the zone, and "white" if they are. The Tracer uses this information to refine traces during phase 1 of collection; see section 6.7, "Five phase collection".
The Tracer doesn't deal with individual client program objects. All details of object allocation and format is delegated to the pool. The Tracer deals with areas of memory defined by pool classes called segments. The segment descriptor contains these fields important to tracing:
In addition, the Tracer maintains a set of traces for which the mutator is grey (and assumes it's black for all other traces), and a summary for the mutator. The mutator is a graph node which consists of the processor registers, and any references in memory that can't be protected against transfers to and from the registers. This is not usually the same as the root set.
Memory barriers5 are used to preserve the reference partitions represented by the traces in the face of mutation by the client process.
Any segment whose grey trace set is not a subset of the mutator's grey trace set is protected from reads by the mutator. This prevents the mutator from reading a reference to a white object when the mutator is black. If the mutator reads the segment, the MPS catches the memory exception and scans the segment to turn it black for all traces in the difference between the sets. (A theoretical alternative would be to "unflip", making the mutator grey for the union of the sets, but this would seriously set back the progress of a trace.)
Any segment whose grey trace set is not a superset of the mutator's grey trace set is protected from writes by the mutator. This prevents the mutator from writing a reference to a white object into a black object. If the mutator writes to the segment, the MPS catches the memory exception and makes the segment grey for the union of the sets. (An alternative would be to "flip", making the mutator black for the difference between the sets, but this would generally be premature, pushing the collection's progress along too fast.)
Any segment which has a summary which is not a superset of the mutator's summary is protected from writes by the mutator3. If the mutator writes to the segment, the MPS catches the memory exception and unions the summary with the mutator's summary, removing the protection. Abstractly, this is the same operation as (2), because the summaries represent reference partitions with respect to zones.
The rank of a reference controls the order in which references are traced while refining the reference partition. All references of lower numbered rank are scanned before any references of higher rank. The current MPS implementation supports four ranks:
Note that the pool which owns the reference may implement additional semantics. For example, when a weak reference is nulled out, the AWL pool nulls out an associated strong reference in order to support weak key hash tables.
Ranks are by no means a perfect abstraction. Parts of the Tracer have to know quite a bit about the special semantics of ambiguous references. The Tracer doesn't take any special action for final and weak references other than to scan them in the right order. It's the pools that implement the final and weak semantics. For example, the MRG pool class is one which implements the sending of near death notices to the client process.
The current implementation of the Tracer does not support segments with more than one rank, but is designed to be extended to do so.
The current MPS ordering puts weak after final, and is equivalent to Java's "phantom references". It would be easy to extend the MPS with additional ranks, such as a weak-before-final (like Java's weak reference).
In order to allow pools to co-operate during a trace the MPS needs a protocol for discovering references. This protocol is the most time critical part of the MPS, as it may involve every object that it is managing. The MPS protocol is both abstract and highly optimized.
Each pool may implement a scan and fix method. These are used to implement a generic scan and generic fix method which dispatch to the pool's method as necessary. The scan method maps the generic fix method over the references in a segment. The fix method preserves the referent of a reference (except when it is applied to weak references), moving it out of the white set for one or more traces.
The most important optimization is part of the generic fix method which is inlined into the scan methods. The generic fix method first looks up the reference in the interesting set (see section 6.7.1, "Phase 1: Condemn"), which takes about three instructions. This eliminates almost all irrelevant references, such as references to generations which aren't being collected, or references to objects not being managed by the MPS.
A second level optimization in the generic fix method checks to see if the reference is to a segment managed by the MPS, and then whether the segment is white for any of the traces for which the reference is being fixed. This eliminates many more references.
Only if a reference passes these tests is the pool's fix method called.
A pool need not implement both scan an fix methods. A pool which doesn't contain references, but does contain garbage collected objects, will have a "fix" method but no "scan" method. Note that such objects are either black or white. A pool which contains references involved in tracing, but not garbage collected objects, will have a "scan" method but no "fix" method. Such a pool would be a pool of roots. A pool with neither method is not involved in tracing, for example, a manually managed pool storing strings.
Roots are objects declared to the MPS by the client process as being a-priori alive. The purpose of tracing is to discover objects which aren't referenced by transitive closure from the roots and recycle the memory they occupy.
The MPS supports various kinds of roots. In particular, a thread can be declared as a root, in which case its stack and registers are scanned during a collection.
Roots have "grey" and "summary" fields just like segments, and may be protected from reads and writes by the mutator using the same rules. However, roots are never white for any trace, since their purpose is to be alive.
The Tracer runs each trace through five phases designed to allow pools to co-operate in the same trace even though they may implement very different kinds of garbage collection.
The set of objects we want to try to recycle, the condemned set is identified and a newly allocated trace is added to the white trace set for the segments containing them.
At this stage, all segments containing any references (even the white ones) are assumed to be grey for the trace, because we don't know whether they contain references to objects in the white set. The roots are made grey for the trace, because they are a-priori alive. The mutator is also assumed to be grey for the trace, because it has had access to all this grey data. Thus we start out with a valid initial reference partition (see section 6.1, "Reference partitions").
We then use any existing reference partitions to reduce the number of grey segments for the trace as much as possible, using this rule: Let P be the set of reference partitions whose white sets are supersets of the new white set. Any node which is in the union of the black sets of P cannot refer to any member of the new white set, and so is also black with respect to it.
In practical terms, we work out the set of zones occupied by the white set. We call this the interesting set. We can then make any segment or root whose summary doesn't intersect with the interesting set black for the new trace. This is just a bitwise AND between two machine words. A pool will usually arrange for a generation to occupy a single zone, so this refinement step can eliminate a large number of grey segments. This is how the MPS implements remembered sets.
In a similar way, the MPS could also use the current status of other traces to refine the new trace. Imagine a large slow trace which is performing a copying collection of three generations. A fast small trace could condemn the old space of just one of the generations. Any object which is black for the large trace is also black for the small trace. Such refinement is not implemented in the MPS at present.
Note that these refinement steps could be applied at any time: they are just refinements that preserve reference partitions. The MPS currently only applies them during the condemn step.
This phase most resembles a write-barrier non-moving garbage collector [Appel 1988]. Any segment "blacker" than the mutator is write protected (see section 6.3, "Segments").
At this point the mutator is grey for the trace. Note that, at any stage, the mutator may be grey or black for different traces independently. In addition, newly allocated objects are grey, because they are being initialized by the mutator.
An object can be moved provided that it is white for any trace for which the mutator is black, because the mutator can't see references to that object.
During phases 2 and 4 the Tracer makes progress by scanning segments which are grey for one or more traces (see section 6.5, "Scanning and Fixing") in order to make them black. Thus we make progress towards a final reference partition (see section 6.1, "Reference Partitions").
Flipping for a set of traces means turning the mutator black for those traces. This entails scanning the mutator's registers and any unprotectable data. The mutator process can't be running while this is happening, so the MPS stops all mutator threads.
This is also the point at which the MPS sets the limit fields of any formatted allocation points to zero, so that unscannable half-allocated objects are invalidated (see section 5.2, "Efficient in-line allocation").
This phase most resembles a read-barrier possibly-moving garbage collector [ref to an example]. Any segment "greyer" than the mutator is read protected (see section 6.3, "Segments").
At this point the mutator is black for the trace. In addition, newly allocated objects are black, and don't need to be scanned.
When the grey set for a trace is empty then it represents a final reference partition. The Tracer looks for segments which are white for the trace and calls the owning pool to reclaim the space occupied by remaining white objects within.
The Memory Management Group at Harlequin was whittled away to nothing as Harlequin slid into financial trouble. Parts of the system are incomplete or have unclear status. A large amount of design documentation exists, but it is fairly disorganized and incomplete. We would like to organize all this information to make the MPS more useful resource.
The MPS was designed around many abstractions that make it very adaptable, but it is not very well packaged and is unlikely to work in new applications without some modification. We would like to improve the MPS to make it easier to apply without modification.
The MPS is currently commercially licensed to Global Graphics for use in the Harlequin® RIP, and to Configura Sverige AB for use in their Configura® business system. We are seeking further licensees.
The MPS project tree is on the web at <http://www.ravenbrook.com/project/mps/>. All of the non-confidential source code and design documentation is available there. This is a mirror of the tree in Ravenbrook's configuration management repository, so it will continue to reflect the development of the MPS.
The MPS resembles the Customisable Memory Management (CMM) framework for C++ [Attardi 1998] and shares some of its design goals. The MPS was not designed for C++, but as a memory manager for dynamic language run-time systems. In fact, it was specifically designed not to require C++.
During our stay at Harlequin we were often frustrated by confidentiality. We were not able to reveal ideas and techniques which we believed were both innovative and useful. The MPS contains many such ideas -- the results of hard work by many people (see section 11, "Acknowledgements"). Now, at last, we can reveal almost all.
The MPS is a highly portable, robust, extensible, and flexible system for memory management, based on very powerful abstractions. It contains many more useful concepts and abstractions not covered in this paper.
We hope that the ideas, techniques, and code of the MPS will be useful. We also hope that companies will license the MPS or engage us to extend and develop it further.
The authors would like to thank all the members of the Memory Management Group for their contributions to the design and implementation of the MPS.
| Name | Period of membership |
|---|---|
| Nick Barnes | 1995-08/1997-11 |
| Richard Brooksby | 1994-02/1997-11 |
| Nick "Sheep" Dalton | 1997-04/1998-07 |
| Lars Hansen | 1998-06/1998-09 |
| David Jones | 1994-10/1999-06 |
| Richard Kistruck | 1998-02/1999-06 |
| Tony Mann | 1998-02/2000-02 |
| Gavin Matthews | 1996-08/1998-11 |
| David Moore | 1995-04/1996-04 |
| Pekka P. Pirinen | 1997-06/2001-04 |
| Richard Tucker | 1996-10/1999-09 |
| P. Tucker Withington | 1994-02/1998-11 |
This isn't a full bibliography for the MPS. The Memory Management Reference Bibliography contains all the papers that influenced the project, and can be found at <http://www.memorymanagement.org/bib/>.
| [Appel 1988] | "Real-time Concurrent Collection on Stock Multiprocessors"; Andrew Appel, John R. Ellis, Kai Li; ACM, SIGPLAN; ACM PLDI 88, SIGPLAN Notices 23, 7 (July 88), pp. 11-20; 1988 |
| [Attardi 1998] | "A Customisable Memory Management Framework for C++"; G. Attardi, T. Flagella, P. Iglio; Software Practice and Experience, 28(11), 1143-1183, 1998; <ftp://ftp.di.unipi.it/pub/Papers/attardi/SPE.ps.gz> |
| [Bartlett 1989] | "Mostly-Copying Garbage Collection Picks Up Generations and C++"; Joel F. Bartlett; Digital Equipment Corporation; 1989; <http://www.research.digital.com/wrl/techreports/abstracts/TN-12.html> |
| [Boehm 1988] | "Garbage collection in an uncooperative environment"; Hans-J. Boehm, Mark Weiser; 1988; Software -- Practice and Experience. 18(9):807-820. |
| [CMMI1.02] | "CMMISM for Systems Engineering/Software Engineering, Version 1.02 (CMMI-SE/SW, V1.02) (Staged Representation)"; CMMI Product Development Team; Software Engineering Institute, Carnegie Mellon University <URL: http://www.sei.cmu.edu/>; 2000-11; CMU/SEI-2000-TR-018, ESC-TR-2000-018; <URL: http://www.sei.cmu.edu/pub/documents/00.reports/pdf/00tr018.pdf>. |
| [Dijkstra 1976] | "On-the-fly Garbage Collection: An Exercise in Cooperation"; E. W. Dijkstra, Leslie Lamport, A. J. Martin, C. S. Scholten, E. F. M. Steffens; 1976; Springer-Verlag. Lecture Notes in Computer Science, Vol. 46. |
| [Dybvig 1993] | "Guardians in a Generation-Based Garbage Collector"; R. Kent Dybvig, Carl Bruggeman, David Eby; 1993; SIGPLAN. Proceedings of the ACM SIGPLAN '93 Conference on Programming Language Design and Implementation, June 1993; <ftp://ftp.cs.indiana.edu/pub/scheme-repository/doc/pubs/guardians.ps.gz> |
| [ANSI/ISO 9899:1990] | "American National Standard for Programming Languages -- C"; ANSI/ISO 9899:1990. |
| [Gilb 1995] | "Software Inspection"; Tom Gilb, Dorothy Graham; Addison-Wesley; 1995; ISBN 0-201-63181-4. |
| [Goguen 1999] | "Memory management: An abstract formulation of incremental tracing"; H. Goguen, R. Brooksby, R. Burstall; In Types '99. Springer Verlag LNCS, 1999. |
| [Hayes 1992] | "Finalization of the Collector Interface"; Barry Hayes; Stanford University; International Workshop on Memory Management, 1992. |
| [MMRef] | "The Memory Management Reference"; Ravenbrook Limited; 2001; <http://www.memorymanagement.org/> |
| [Moon 1984-08] | "Garbage Collection in a Large Lisp System"; David Moon; 1984; ACM. Symposium on Lisp and Functional Programming, August 1984. |
| [Pirinen 1998] | "Barrier techniques for incremental tracing"; Pekka P. Pirinen; Harlequin Limited; 1998; ACM. ISMM'98 pp.20-25; <http://www.acm.org/pubs/citations/proceedings/plan/286860/p20-pirinen/> |
| [RB 1995-11-01] | "MM/EP-Core Requirements"; Richard Brooksby; Harlequin Limited; 1995-11-01; confidential. |
| [RB 1996-09-02] | "Allocation Buffers and Allocation Points"; Richard Brooksby; Harlequin Limited; 1996-09-02; <http://www.ravenbrook.com/project/mps/master/mminfo/design/mps/buffer/> |
| [RB 1996-10-02a] | "Dylan Requirements"; Richard Brooksby; Harlequin Limited; 1996-10-02; <http://www.ravenbrook.com/project/mps/master/mminfo/req/dylan/> |
| [RB 1996-10-02b] | "The Design of the MPS Tracer"; Richard Brooksby; Harlequin Limited; 1996-10-02; <http://www.ravenbrook.com/project/mps/master/mminfo/design/mps/tracer/> |
| [RB 1996-10-11] | "An Overview of the Memory Management Group and Projects"; Richard Brooksby; Harlequin Limited; 1996-10-11; <http://www.ravenbrook.com/project/mps/master/mminfo/overview/mm/> |
| [RB 1997-01-28] | "The Architecture of the MPS"; Richard Brooksby; Harlequin Limited; 1997-01-28; <http://www.ravenbrook.com/project/mps/master/mminfo/design/mps/arch/> |
| [Ungar 1984] | "Generation Scavenging: A Non-disruptive High Performance Storage Reclamation Algorithm"; Dave Ungar; 1984; ACM, SIGSOFT, SIGPLAN Practical Programming Environments Conference. |
| 2002-01-30 | RB | Created from notes. |
| 2002-01-31 | RB | Wrote introduction, background, and history. |
| 2002-02-01 | RB | Wrote architecture overview, implementation overview, and key features. Added sections for key technology, availability, conclusion, acknowledgements. Compiled list of MM Group members for acknowledgements section. Investigated ACM document licensing and created compatible licence. Wrote pool class table with descriptions of classes. |
| 2002-02-02 | RB | Finished outline, creating headings for all notes. Created abstract. Improved history section. Added section on in-line allocation. |
| 2002-02-06 | RB | Drafted sections about tracing abstractions and algorithms. Added start and end dates for remaining group members. Converted the pool class list from a table to a bunch of subsections. Added sections on reference ranks, the scan/fix protocol, and other parts of the Tracer. Fixed issues raised by NB in review. Added section on roots. Discussed allocation colour. Added conclusions and some related work. |
| 2002-02-07 | RB | Responded to review comments from Pekka P. Pirinen, Gavin Matthews, Nick Levine, Richard Kistruck, and Tucker Withington. |
Copyright © 2002 Ravenbrook Limited. This document is provided "as is", without any express or implied warranty. You may make and distribute copies of all or part of this document provided that you do not make copies for profit or commercial advantage, and that copies bear this notice and the full citation at the head of the document.
| 1 | The details of the Harlequin® RIP configuration and the the RIP-specific pool class implementations are confidential, and not available under an open source licence. |
| 2 | The MPS can be compiled with various flags to give different varieties. The "cool" varieties are intended for debugging and testing. The "hot" varieties are for delivery. Some level of internal consistency checking is present in all varieties. |
| 3 | The current implementation of the MPS assumes that the mutator has a universal summary. In other words, it assumes that the mutator could refer to any zone. This could be improved. |
| 4 | Ironically, a lot of clever design went into the interfaces (MPM and the plinth) to make robust and efficient binary interfaces for a closed-source MPS library. When the client has access to source code, a host of compiler switches may be more appropriate. |
| 5 | A memory barrier is an abstraction for any technology that can prevent the mutator from reading from or writing to particular objects without invoking the memory manager first. The MPS uses memory protection (hardware memory barrier) for this, but could easily be adapted to a software barrier (if we have control over the compiler). The MPS abstraction of memory barriers distinguishes between read and write barriers, even if the specific environment cannot. |
$Id: //info.ravenbrook.com/project/mps/doc/2002-01-30/ismm2002-paper/ismm2002.html#3 $