Perforce Defect Tracking Integration Project
This manual is the Perforce Defect Tracking Integration Advanced Administrator's Guide. It describes methods of administering the P4DTI that are outside the scope of the Perforce Defect Tracking Integration Administrator's Guide because they require a higher level of expertise (see "Required experience" below).
This document is intended for P4DTI administrators. Ordinary users of the defect tracker or Perforce should read the Perforce Defect Tracking Integration User's Guide.
This guide does not describe how to install, maintain, or perform ordinary configuration and administration of the P4DTI. Read the Perforce Defect Tracking Integration Administrator's Guide.
To do the things described in this guide, you must have the following experience:
The P4DTI
selects the issues that get replicated from the defect tracker using the
replicate_p function. To select
the issues that get replicated, edit this function in the file config.py in the installation directory.
Normally, the P4DTI replicates all issues created or modified
after the start_date,
but you can modify this function to further restrict the issues. See section 5.1, "P4DTI configuration", of the Perforce Defect
Tracking Integration Administrator's Guide for more details of the start_date parameter.
Note: after an issue starts being replicated, it
continues to be replicated, even if it no longer matches the replicate_p criteria.
The function is passed one argument, the issue, in the form of a Python dictionary that maps field names (strings) to field values. If the function returns 1, the issue is replicated. If it returns 0, the issue is not.
The replicate_p function does not have to check the start_date configuration parameter. The start_date is always honored by the P4DTI, in addition to any test made by replicate_p.
Example 1. This example restricts replication to issues belonging to project 6:
def replicate_p(issue): return issue["PROJECTID"] == 6
Example 2. Suppose you want to replicate only those issues where
the "Issue type" is BUG. The issue type is stored in the
ISSUETYPE field in the issue table, and the value of that
field is the ID field of the appropriate record in the
SELECTIONS table [TeamShare 2002-01-30a]. You need to specify a replicate_p function like this:
def replicate_p(issue): return issue["ISSUETYPE"] == 1
This example assumes the value 1 is the value for the issue type
BUG. To determine the value for an issue type, look in the
SELECTIONS table, find the record where PREFIX
is BUG, and use the ID field from that record.
See section 6, "Querying the TeamTrack
database", for how to do this.
This example restricts replication to unresolved issues in the "horseshoe" product:
def replicate_p(issue): return (issue["product"] == "horseshoe" and issue["resolution"] == "")
By default, the P4DTI requires users to create issues using the defect tracker. It ignores jobs created in Perforce. The P4DTI can be configured to transform new jobs created in Perforce into new issues in the defect tracker.
To cause the P4DTI to replicate jobs created in Perforce, add two
functions to the end of config.py: replicate_job_p and prepare_issue.
Note: this feature is not available for TeamTrack 4.5. You must upgrade to TeamTrack 5.0 or later.
replicate_job_p function The replicate_job_p function chooses the jobs in
Perforce that get added to the defect tracker. The function takes the
newly-created job as its argument, in the form of a Python dictionary
that maps field names (strings) to field values (strings). If it returns
1, the job is added to the defect tracker and replicated thereafter. If
it retuns 0, the job is not replicated.
Note: after a job starts being replicated it,
continues to be replicated, even if it no longer matches the replicate_job_p criteria.
If you want all newly-created jobs to be translated and added to the
defect tracker, write a replicate_job_p
function as follows:
def replicate_job_p(job):
return 1
To replicate newly-created jobs for projects called "horseshoe" and
"nail", add the PROJECTID field to the replicated_fields configuration parameter;
this field gets replicated to the job field "Project" in Perforce; write
a replicate_job_p function as follows:
def replicate_job_p(job): return job["Project"] in ["horseshoe", "nail"]
To replicate newly-created jobs for products called "horseshoe" and
"nail", add the product field to the replicated_fields configuration parameter;
this field gets replicated to the job field "Product" in Perforce; write
a replicate_job_p function as follows:
def replicate_job_p(job): return job["Product"] in ["horseshoe", "nail"]
prepare_issue function The P4DTI
does its best to build the new issue, but the defect tracker might
require fields that can't be translated automatically from fields in the
job. So the P4DTI calls the prepare_issue function to complete the
transformation of a new job in Perforce to an issue in the defect
tracker, by supplying values for fields that can't be translated
automatically.
The function takes two arguments (issue,
job):
issueThe partly-constructed issue, in the form of a Python dictionary that maps field names (strings) to field values. For example, in TeamTrack this might be:
{
"STATE": 17,
"OWNER": 9,
"TITLE": "The widgets are specified in imperial units (ft/lb/s).\n",
"DESCRIPTION": "But 80% of customers use ISO 31, so we should use m/kg/s.\n"
"PRIORITY": 32,
"PROJECTID": 17,
"ISSUETYPE": 0,
"SUBMITTER": 9,
}jobThe job, in the form of a Python dictionary that maps field names (strings) to a field values (strings). For example:
{
"Job": "job000123",
"State": "verified",
"Owner": "gdr",
"Date": "2001/10/11",
"Title": "The widgets are specified in imperial units (ft/lb/s).\n",
"Description": "But 80% of customers use ISO 31, so we should use m/kg/s.\n",
"Priority": "high",
"Project": "widget",
} The function must modify issue so that
it is valid for the defect tracker. The following sections explain what
"valid" means for TeamTrack (section 3.2.1)
and Bugzilla (section 3.2.2).
In the TeamTrack integration, new issues must have a valid value for the following fields:
ISSUETYPE The ID of a record in the SELECTIONS table in the TeamTrack database
(look in the PREFIX field for the name of
the issue type).
If the ISSUETYPE field is not one of the
replicated_fields, or if the value in the job
is not the name of an issue type, then the P4DTI picks 0
for issue['ISSUETYPE'], so the issue has no
type, just a number. If this is not appropriate, you must supply a
suitable value.
PROJECTID The ID of a record in the PROJECTS table in the TeamTrack database (look
in the NAME field for the project
name).
If the PROJECTID field is not one of the
replicated_fields, or if the value in the job
is not the name of a project, then the P4DTI sets issue['PROJECTID'] to 0, which is not a valid project, so the issue
can't be created. You must supply a suitable value.
You can use the prepare_issue function
to supply default values for other fields in TeamTrack. See the
TeamTrack database schema [TeamShare 2002-01-30a] for the full details.
If PROJECTID and ISSUETYPE are both in the replicated_fields, then you can omit this
function altogether, since these fields are translated
automatically.
The following function supplies a default project and issue type if necessary:
def prepare_issue(issue, job): if issue["PROJECTID"] == 0: issue["PROJECTID"] = 17 # My default project if issue["ISSUETYPE"] == 0: issue["ISSUETYPE"] = 1 # BUG
In the Bugzilla integration, new issues must have a valid value for the following fields:
product The the name of a product in the Bugzilla products table.
If the product field is not one of the
replicated_fields, then the P4DTI picks the
empty string for issue["product"] (except
when there's only one product, in which case the P4DTI picks that product).
componentThe name of a component of the product to which the issue belongs.
If the component field is not one of the
replicated_fields, then the P4DTI picks the
empty string for issue["component"] (except
when there's only one component of the product, in which case the P4DTI picks that
component).
versionThe name of a version of the product to which the issue belongs.
If the version field is not one of the
replicated_fields, then the P4DTI picks the
empty string for issue["version"] (except
when there's only one version of the product, in which case the P4DTI picks that
version).
You can use the prepare_issue function
to supply default values for other fields in Bugzilla. See the Bugzilla
database schema [NB
2000-11-14a] for details.
The following function supplies a default product, component and version if necessary:
def prepare_issue(issue, job): default_component = { "horseshoe": "user interface", "nail": "manufacturing", } default_version = { "horseshoe": "1.7", "nail": "2.3beta", } if issue["product"] == "": issue["product"] = "horseshoe" product = issue["product"] if issue["component"] == "": issue["component"] = default_component[product] if issue["version"] == "": issue["version"] = default_version[product]
Migration is the process of loading your Perforce jobs into the defect tracker.
Note: this feature is not available for TeamTrack 4.5. You must upgrade to TeamTrack 5.0 or later.
The migration procedure has an important limitation: you can't keep your old jobspec. You have to migrate to a system in which the P4DTI chooses your jobspec for you based on the fields you replicate from the defect tracker.
If you need to keep your old jobspec, then you must use the "advanced configuration" approach. This is outside the scope of the manual, but is documented in [GDR 2000-10-16, 8.6]. Contact Perforce technical support if you need to do this.
Create a Perforce server for testing.
Create a defect tracker for testing. If you have existing defect tracking data, make a copy that includes your workflow and a representative sample of your existing issues.
Set up and test the P4DTI on the test Perforce server and test defect tracker, following the instructions in the Perforce Defect Tracking Integration Administrator's Guide. Test the integrated system and verify that the workflow is correct.
Record the jobspec created by the P4DTI (for example, by running a command
like p4 jobspec -o > saved-jobspec, or
by printing it out). This jobspec is used in configuring the
translation step of the migrator. (See section
4.7, "Translating to the new jobspec".)
Replace the test Perforce server with a server that has a copy of all your jobs and fixes. (Create a checkpoint of your main Perforce server and restore it onto a new empty Perforce server. See chapter 2, "Supporting Perforce: Backup and Recovery", of the Perforce 2001.1 System Administrator's Guide.)
Set up and test migration from the test Perforce server to the test defect tracker, as described in section 4.2, "How to migrate".
Apply any workflow changes you made on your test defect tracker to your main defect tracker server.
When you are confident that you have the correct configuration, proceed to section 4.1.3, "Going live with the P4DTI with migration".
After you have configured and tested the P4DTI with migration, follow these steps to make the system available to your users:
Ask your users to stop using the defect tracker and Perforce server.
Make a backup up of your Perforce repository and your defect tracker database, in case there are any serious problems.
Perforce: make a checkpoint of your Perforce server; see chapter 2, "Supporting Perforce: Backup and Recovery", of the Perforce 2001.1 System Administrator's Guide.
TeamTrack: start the TeamTrack Administrator; select "Copy Database" from the "File" menu; see section 16, "Copying a Database", of the TeamTrack Administrator Manual 5.5.
Bugzilla: run mysqldump -u user
database > backup-file. See section 4.4.1,
"Database Backups", of the MySQL ManuaL.
Edit your config.py file to point to your main Perforce and defect tracker servers.
Run the migration and check the results (4.10).
Start the P4DTI.
Migration cannot be done automatically by the P4DTI, because the data in Perforce is in a very different format from the defect tracker, and the way your workflow is implemented in Perforce is likely to be different from the way it's implemented in the defect tracker.
Here is an overview of migration. The details of each step are covered in the following sections.
Prepare the Perforce data for migration:
Write Python functions in your config.py to do the following:
Migrate the selected jobs to the defect tracker (4.10).
Give every Perforce user a name and e-mail address, to enable the P4DTI to correctly match users in Perforce to users in TeamTrack (see section 3.5, "User accounts" of the Perforce Defect Tracking Integration Administrator's Guide), or automatically make user accounts in Bugzilla for each Perforce user (see section 4.4, "Making defect tracker user accounts").
In your defect tracker, create a user account for every Perforce user who originates or works on issues.
TeamTrack: create users using the TeamTrack Administrator application. See the TeamTrack Administrator Manual for your release of TeamTrack.
Bugzilla: follow these steps to create the users automatically:
Specify dbms_host, dbms_port, dbms_user and dbms_password in config.py if you haven't already done so.
Specify these two configuration parameters in config.py (unless you're happy with the
default values):
migrated_user_groups is a list of Bugzilla
groups. Automatically created users in Bugzilla belong to all the
groups in this list. For example, if migrated_user_groups = ["editbugs",
"canconfirm"] then users can edit and confirm bugs. The
default value is [] (that is, users
belong to no groups).
To see the Bugzilla groups and their meaning, log into Bugzilla as an administrator and select "edit groups" from the options at the bottom right.
migrated_user_password is a string.
Automatically created users have this password in Bugzilla. For
example, if migrated_user_password =
"spong" then users have password "spong". The default value
is "password".
Go to the P4DTI installation directory.
Run the command python
migrate_users.py.
If you change the jobspec, Perforce doesn't update its existing jobs to match, so some jobs might be inconsistent with the revised jobspec. Examples: a "required" field that is missing from some jobs; a "select" field for which some jobs have an illegal value. These problems prevent the P4DTI from reading the jobs.
To find inconsistencies, go to the P4DTI installation directory and run the
command python check_jobs.py (it takes
about a minute for every thousand jobs on a typical system). For
example:
$ python check_jobs.py
(P4DTI-10081) Job 'job000024' doesn't match the jobspec:
(P4DTI-7087) Error detected at line 11.
Value for field 'Status' must be one of open/suspended/closed.
Fix these jobs so that they match the jobspec. When this is done, you'll get the following output:
$ python check_jobs.py
(P4DTI-10092) All jobs match the jobspec.
To select the jobs to migrate, add the function migrate_p to
the end of config.py.
The migrate_p(job) function determines whether to
migrate a job to the defect tracker. The job argument is
the job being considered for migration (in the old jobspec), in the form
of a dictionary that maps field names (strings) to field values (strings).
If it returns 1, the job is migrated. If it returns 0, the job is not
migrated.
migrate_pExample 1. To migrate all jobs:
def migrate_p(job):
return 1
Example 2. To migrate only open jobs:
def migrate_p(job):
return job["Status"] == "open"
Example 3. To migrate only jobs in the "horseshoe" and "nail" projects:
def migrate_p(job):
return job["Project"] in ["horseshoe", "nail"]
Add the function translate_jobspec to the end of
config.py.
The translate_jobspec function translates a job
from the old jobspec (before migration) to the new jobspec (after
migration). The old job is passed as the single argument, in the form
of a dictionary that maps field names (strings) to field values
(strings). The new job must be returned in the same form (it's OK to
update and return the argument).
Example Perforce job in the old jobspec:
Job: job000123
Status: closed
User: gdr
Date: 2001/10/11
Description:
The widgets are specified in imperial units (ft/lb/s).
But 80% of customers use ISO 31, so we should use m/kg/s.
Priority: high
Project: widget
|
You plan to set replicated_fields=["DESCRIPTION",
"PRIORITY", "PROJECTID"], so jobs look like this in the new
jobspec:
Job: job000123
State: verified
Owner: gdr
Date: 2001/10/11
Title:
The widgets are specified in imperial units (ft/lb/s).
Description:
But 80% of customers use ISO 31, so we should use m/kg/s.
Priority: high
Project: widget
|
So these changes are needed:
The old jobspec has a single "Description" field, but the new jobspec has both a "Title" (one line) and a "Description" (many lines). So split the old description so that its first line becomes the new title.
Rename the "Status" field as "State" and "User" field as "Owner".
In the old jobspec, status is "open", "closed" or "suspended". In the new jobspec, state is "_new", "assigned", "resolved" or "verified". So translate "open" to "assigned", and both "closed" and "suspended" to "verified".
Here's a translate_jobspec function
that implements the changes described above:
def translate_jobspec(job): # Description -> Title + Description import string desc = job.get("Description", "") newline = string.find(desc, "\n") job["Title"] = desc[:newline] job["Description"] = desc[newline+1:] # User -> Owner job["Owner"] = job.get("User", "(None)") # Status -> State status = job.get("Status", "open") if status == "open": job["State"] = "assigned" else: job["State"] = "verified" return job
Example Perforce job in the old jobspec:
Job: job000123
Status: closed
User: gdr
Date: 2001/10/11
Description:
The widgets are specified in imperial units (ft/lb/s).
But 80% of customers use ISO 31, so we should use m/kg/s.
Priority: high
Project: widget
|
You plan to set replicated_fields=["resolution",
"short_desc", "priority", "product"], so jobs look like this in
the new jobspec:
Job: job000123
Status: closed
Assigned_To: gdr
Date: 2001/10/11
Summary:
The widgets are specified in imperial units (ft/lb/s).
Description:
But 80% of customers use ISO 31, so we should use m/kg/s.
Resolution: FIXED
Priority: P1
Product: widget
|
So these changes are needed:
The old jobspec has a single "Description" field, but the new jobspec has both a "Summary" (one line) and a "Description" (many lines). So split the old description so that its first line becomes the new summary.
Rename the "User" field as "Assigned_To".
In the old jobspec, the status is "open", "closed" or "suspended". In the new jobspec, the status is represented by a combination of "Status" and "Resolution" fields. Translate status as shown in the table below.
| Old status | New status | Resolution |
|---|---|---|
"open" |
"assigned" |
"" |
"closed" |
"closed" |
"FIXED" |
"suspended" |
"closed" |
"LATER" |
Here's a translate_jobspec function that
implements all the changes discussed above:
def translate_jobspec(job): # Description -> Summary + Description import string desc = job.get("Description", "") newline = string.find(desc, "\n") job["Summary"] = desc[:newline] job["Description"] = desc[newline+1:] # User -> Assigned_To job["Assigned_To"] = job.get("User", "") # Translate Status -> Status + Resolution status_map = { "open": ("assigned", ""), "closed": ("closed", "FIXED"), "suspended": ("closed", "LATER"), } (status, resolution) = status_map[job.get("Status", "open")] job["Status"] = status job["Resolution"] = resolution return job
Jobs translated to the new jobspec might not be suitable for
submission to the defect tracker. The defect tracker might have
additional constraints, or require fields that can't be translated from
fields in the job. You must write a prepare_issue function as described in section 3.2, "The prepare_issue function".
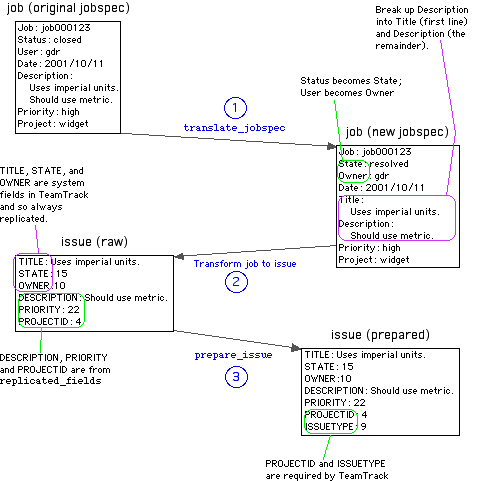
Figure 1 shows a summary of the translate, transform, and preparation steps of the migration process:
Translate the job from the
old jobspec to the new jobspec using the translate_jobspec
function.
The P4DTI transforms the job to an
issue by converting each field in replicated_fields
and any system fields.
Prepare for submission to
the defect tracker using the prepare_issue
function.
Make a checkpoint of the Perforce server as described in chapter 2, "Supporting Perforce: Backup and Recovery", of the Perforce 2001.1 System Administrator's Guide.
Go to the P4DTI installation directory and run the command
python migrate.py. If it succeeds, it
prints output like this. (If you see no output, then your migrate_p
function isn't matching any jobs.)
2001-11-14 12:34:13 (P4DTI-8920) Migrated job 'job000001' to issue 'BUG00001'.
2001-11-14 12:34:13 (P4DTI-8920) Migrated job 'job000002' to issue 'BUG00002'.
2001-11-14 12:34:13 (P4DTI-8206) -- Added fix for change 3326 with status closed.
...
2001-11-14 12:35:02 (P4DTI-8953) Migration completed.
Notes for Bugzilla users:
The P4DTI locks the Bugzilla database while migrating, so no-one can use Bugzilla until migration completes.
If you've specified a value for bugzilla_directory, you'll see the message
"Running processmail for %d bugs..." after the last job is migrated and
before the "Migration completed" message appears. This is because
Bugzilla's processmail script is being run
for each migrated issue. (If you don't want notifications to be sent
when migrating, set bugzilla_directory=None
while migrating and reset it afterwards.)
Handle errors (see section 4.11).
When you've fixed the problem, run python
migrate.py again. Provide the command-line option -s JOBNAME to start migrating at a
particular job. For example, if migration failed because of a problem
job000123, then continue migrating with python
migrate.py -s job000123.
In the defect tracker, verify that all the Perforce jobs you
want to replicate are present and that the values in all fields are
correct. If not, fix the problems by hand, or edit the migrate_p, translate_jobspec and prepare_issue functions to correct the problem, and run migration
again.
Replace the existing jobs in Perforce with jobs replicated from the defect tracker's database by refreshing them as described in section 9.2, "Refreshing jobs in Perforce", of the Perforce Defect Tracking Integration Administrator's Guide.
Check the consistency of the replicated data by running the
consistency checker as described in section 7.3,
"Checking data consistency", of the Perforce Defect Tracking
Integration Administrator's Guide. If this consistency check
fails, fix the problems by hand, or restore your Perforce server from
the checkpoint you made earlier, edit the migrate_p, translate_jobspec and prepare_issue functions to correct the problem
and run migration again.
Start the P4DTI as described in section 5.5, "Starting and stopping the replicator manually", of the Perforce Defect Tracking Integration Administrator's Guide.
These kinds of error are likely to be encountered during migration:
The P4DTI can't translate a user. For example:
(P4DTI-9231) Translating job field 'User' (value 'spong') to issue field 'assigned_to'...
(P4DTI-921X) Migrating job 'job000174'...
Bugzilla module error (P4DTI-514X) There is no Bugzilla user corresponding to Perforce user 'spong'.
This can happen even if you translated all Perforce users in section 4.4, because a deleted Perforce user might still appear in fields in jobs.
Choose the most appropriate of these four solutions:
Add the user to Perforce and to the defect tracker. (You need a spare Perforce licence and a spare TeamTrack licence if migrating to TeamTrack.)
Bugzilla: Add the user to Bugzilla (only) and edit the job so that the user's e-mail address appears instead of the user name. (The P4DTI can match this address to the user in Bugzilla without the user needing to exist in Perforce.)
TeamTrack: Add the user to TeamTrack (only) with the same user name as in Perforce. (You need a spare TeamTrack licence.)
Edit the job and replace the non-existent user with a real user.
The P4DTI can't transform a job to an issue; for example:
(P4DTI-9231) Translating job field 'State' (value 'suspended') to issue field 'STATE'...
(P4DTI-921X) Migrating job 'job000174'...
(P4DTI-6426) No TeamTrack state corresponding to Perforce state 'suspended'.
The translate_jobspec function has failed to
translate all values in Perforce. (In the example error, it must
translate the Perforce status suspended to a TeamTrack
state, as shown in the example in section
4.7.1.)
The P4DTI can't create an issue in the defect tracker; for example:
(P4DTI-921X) Migrating job 'job000174'...
(P4DTI-522X) Can't create Bugzilla bug without component field.
The prepare_issue function has failed to meet all
the defect tracker constraints. (In the example error, it needs to
provide a value for the component field, as shown in the example in section 3.2.4.)
The P4DTI can be set up to replicate defects from a single defect tracker to multiple Perforce servers. For example, if you have several development groups, each with their own Perforce server, you can set up the P4DTI to replicate the issues for each group to the appropriate Perforce server.
Note 1: this feature is not available for TeamTrack 4.5 or early TeamTrack 5.0 releases. You must upgrade to TeamTrack build 50207 or later.
Note 2: the P4DTI doesn't support integration between one Perforce server and multiple defect tracking servers.
To replicate to multiple Perforce servers:
Install a copy of the P4DTI for each Perforce server, as described in readme.txt.
Configure each copy of the P4DTI. The following configuration parameters must be different for each copy:
rid, so the replicators can distinguish the
issues they are responsible for. sid and p4_server_description, so the defect tracker
can report the Perforce server to which the issue is replicated. p4_port, so each replicate can find its
Perforce server. (If you have different users and passwords on each
Perforce server, change p4_user and p4_password as well). replicate_p, so that the replicators don't try
to replicate the same issues. changelist_url and job_url (if you use these features), so that
the defect tracker can provide links to the correct server to provide
more information changelists and jobs. Start and manage each P4DTI as described in the Perforce Defect Tracking Integration Administrator's Guide.
Note that there's no way to move issues from one Perforce server to
another. Once an issue is replicated to one Perforce server then
continues to be replicated to that server, even if it later matches the
replicate_p function for another replicator.
If it's doubtful which development group is going to work on an issue,
then you must design your workflow so that issues don't get replicated
until it's clear who's going to work on them.
For example, you might have a replicate_p function like this:
def replicate_p(issue):
return (issue["PROJECTID"] in [4,7,11]
and issue["STATE"] == 19)
(where state 19 is "Assigned"), so that you get an opportunity to take a decision on the issue and possibly move it to a different project before it gets replicated.
You have Perforce servers for your development groups in France and
Germany and a single TeamTrack server. Projects 4, 7 and 11 are worked
on in France and projects 5, 6, 9 and 10 are worked on in Germany. So
set up one P4DTI copy with the following in config.py:
rid = "replicator_fr"
sid = "france"
p4_port = "perforce.company.fr:1666"
p4_server_description = "French development group"
changelist_url = "http://perforce.company.fr/cgi-bin/perfbrowse?@describe+%d"
job_url = "http://perforce-company.fr/cgi-bin/perfbrowse?@job+%s"
def replicate_p(issue):
return issue["PROJECTID"] in [4,7,11]
and the other with the following:
rid = "replicator_de"
sid = "germany"
p4_port = "perforce.company.de:1666"
p4_server_description = "German development group"
changelist_url = "http://perforce.company.de:8080/%d?ac=10"
job_url = None
def replicate_p(issue):
return issue["PROJECTID"] in [5,6,9,10]
To write replicate_p and prepare_issue functions, you need to know the
key values for the tables in the TeamTrack database.
You can examine the TeamTrack database using Microsoft SQL Server,
or you can use the teamtrack_query.py
script that comes with the P4DTI.
Use the TeamTrack database schema [TeamShare 2002-01-30a] to determine which table you need to query and how to understand the output.
To display the contents of the TeamTrack database:
Edit config.py and specify teamtrack_server, teamtrack_user and teamtrack_password.
Run the command python teamtrack_query.py
TABLE to query a table and show all fields for all
records.
Run the command python teamtrack_query.py
TABLE FIELD1 FIELD2 ... to find the contents
of a table and restrict the output to the named fields.
Add the option -q QUERY to
restrict the output to the rows matching the query.
You want to replicate issues from the projects "Horseshoe" and
"Nail". The TeamTrack database schema [TeamShare
2002-01-30a] says that the value in an issue's
PROJECTID field is the ID field of a record in
the PROJECTS table. So you run this command:
> python teamtrack_query.py PROJECTS ID NAME +------+----------------+ | ID | NAME | +------+----------------+ | 1 | Base project | | 2 | Horseshoe | | 3 | Cart | | 4 | Nail | | ... | ... | +------+----------------+
So you can write:
def replicate_p(issue):
return issue["PROJECTID"] in [2,4]
When a job is created in Perforce, you want to create an issue in
TeamTrack with issue type "BUG". The TeamTrack database schema [TeamShare
2002-01-30a] says that an issue type is the ID field of
a record in the SELECTIONS table where the
PREFIX field gives the prefix for the issue id. So you run
the command:
> python teamtrack_query.py SELECTIONS ID PREFIX NAME +------+----------+------------------------+ | ID | PREFIX | NAME | +------+----------+------------------------+ | 0 | | (None) | | 1 | BUG | Bug report | | 2 | ENH | Enhancement proposal | | ... | ... | ... | +------+----------+------------------------+
So you can write:
def prepare_issue(issue):
issue["ISSUETYPE"] = 1
| [GDR 2000-09-04] | "TeamTrack database schema extensions for integration with Perforce"; Gareth Rees; Ravenbrook Limited; 2000-09-04; <http://www.ravenbrook.com/ project/p4dti/version/1.5/ design/teamtrack-p4dti-schema/>. |
| [GDR 2000-10-16] | "Perforce Defect Tracking Integration Integrator's Guide"; Gareth Rees; Ravenbrook Limited; 2000-10-16. |
| [MySQL 2001] | "MySQL Manual"; MySQL; 2001. |
| [NB 2000-11-14a] | "Bugzilla database schema"; Nick Barnes; Ravenbrook Limited; 2000-11-14. |
| [Perforce 2001-06-18b] | "Perforce 2001.1 System Administrator's Guide"; Perforce Software; 2001-06-18; <http://www.perforce.com/perforce/doc.011/manuals/p4sag/>, <ftp://ftp.perforce.com/pub/perforce/r01.1/doc/manuals/p4sag/p4sag.pdf>. |
| [RB 2000-08-10a] | "Perforce Defect Tracking Integration Administrator's Guide"; Richard Brooksby; Ravenbrook Limited; 2000-08-10. |
| [TeamShare 2002-01-30a] | "TeamTrack Database Schema (Database Version: 55006)"; TeamShare; 2001-04-30. |
| [TeamShare 2002-01-30b] | "TeamTrack Administrator Manual 5.5"; TeamShare; 2002-01-30. |
| 2001-11-14 | GDR | Branched from Administrator's Guide. |
| 2001-11-21 | GDR | Note the password for migrated Bugzilla users. |
| 2001-11-22 | GDR | Documented the need to refresh Perforce jobs after migrating if you want to move to an integrated system. |
| 2001-11-23 | RB | Substantial revision, editing for clarity and adding details where necessary. Devised and added a section giving a plan for installing with migration. |
| 2001-11-25 | GDR | Added material on replicating to multiple Perforce servers and on querying the TeamTrack database. |
| 2001-11-27 | GDR | Added instructions for setting migrated_user_groups and migrated_user_password. Documented the -s option to the migration script. |
| 2002-01-10 | GDR | Noted non-availability of some advanced features in old TeamTrack releases. |
| 2002-02-04 | GDR | Explain how to back up and restore databases. Refer to TeamTrack 5.5 documentation. |
This document is copyright © 2001 Perforce Software, Inc. All rights reserved.
Redistribution and use of this document in any form, with or without modification, is permitted provided that redistributions of this document retain the above copyright notice, this condition and the following disclaimer.
This document is provided by the copyright holders and contributors "as is" and any express or implied warranties, including, but not limited to, the implied warranties of merchantability and fitness for a particular purpose are disclaimed. In no event shall the copyright holders and contributors be liable for any direct, indirect, incidental, special, exemplary, or consequential damages (including, but not limited to, procurement of substitute goods or services; loss of use, data, or profits; or business interruption) however caused and on any theory of liability, whether in contract, strict liability, or tort (including negligence or otherwise) arising in any way out of the use of this document, even if advised of the possibility of such damage.