Ravenbrook / Projects / Perforce Defect Tracking Integration / Master Product Sources / Design
Perforce Defect Tracking Integration Project
This document describes the design, data structures and algorithms of the Perforce defect tracking integration's replicator daemon.
The purpose of this document is to make it possible for people to maintain the replicator, and to adapt it to work on new platforms and with new defect tracking systems, to meet requirements 20 and 21.
This document will be modified as the product is developed.
The readership of this document is the product developers.
This document is not confidential.
For each pair consisting of a defect tracking server and Perforce
server where there is replication going on there is a replicator object.
The replicator object in Python belongs to the replicator
class in the replicator module, or to a subclass.
These replicator objects do not communicate with each other. This makes their design and implementation simple. (There may be a loss of efficiency by having multiple connections to a defect tracking server, or making multiple queries to find cases that have changed, but I believe that the gain in simplicity is worth the risk of loss of performance.)
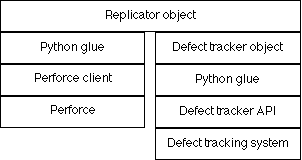
The replicator object is completely independent of the defect tracking system: all defect tracking system specific code is in a separate object [RB 2000-11-08]. This makes it easier to port the integration to a new defect tracking system (requirement 21).
Each replicator object is paired with a defect tracker object, which
represents the connection to the defect tracking system. The defect
tracker object in Python belongs to a subclass of the
defect_tracker class in the replicator module
[RB 2000-10-16, 7.1].
The defect tracker object will in turn use some interface to connect to the defect tracking system. This may be an API from the defect tracking vendor, or a direct connection to the database.
The structure of the replicator is illustrated in figure 1.
Figure 1. The
replicator structure
Each replicator has a unique identifier. This is a string of up to 32 characters that matches the syntax of an identifier in C (only letters, digits and underscores, must start with a letter or underscore). The replicator identifier can be used as a component of other identifiers where it is necessary to distinguish between different replicators. The replicator identifier makes it possible to support organizations with multiple defect tracking servers and/or multiple Perforce servers (requirements 96, 97 and 98).
When the integration is installed, the administrator must extend the
Perforce jobspec P4DTI-rid field which contains the
identifier of the replicator which replicates that job (see section 4.3). The integration must extend the
defect tracking system's issue table the first time it runs with a field
that will contain a replicator identifier. This field will not be
filled in until the issue is selected for replication; see section 2.9.
A consequence of this design is that each job is replicated to one and only one issue (and vice versa).
Each Perforce server has a unique identifier. This is a string of up to 32 characters that matches the syntax of an identifier in C (only letters, digits and underscores, must start with a letter or underscore). The server identifier makes it possible to support organizations with multiple Perforce servers (requirements 97 and 98).
The integration must extend the defect tracking system's issue table the first time it runs with a field that will contain the Perforce server identifier of the server the issue is replicated to. This field will not be filled in until the issue is selected for replication; see section 2.9.
Note that the design of the replicator means that each replicator corresponds to exactly one Perforce server. However, this is an incidental feature of the implementation, not a principle on which you can depend. So make sure you always bear in mind the possibility that a replicator may replicate to multiple Perforce servers.
At initialization time, each defect tracker object will provide to the defect tracking system the Perforce servers it supports replication to (for example, it may put this information in a table in the defect tracking database). This allow the defect tracking system to present the name of the server that each issue is replicated to.
The replicator needs to find the issue corresponding to a job and the
job corresponding to an issue. At installation time, the administrator
must extend the Perforce jobspec with a P4DTI-issue-idfield
which, if the job is being replicated, will contain a string from which
the defect tracker object can deduce the identifier of the corresponding
issue (see section 4.2). (I expect this to
be issue identifier itself, if it is a string, or a string conversion,
if it is a number, but any string representation is allowed.) The
integration must extend the defect tracking system's issue table the
first time it runs with a field that will contain the name of the
corresponding job.
The choice of jobname for new jobs that correspond to issues is up to the defect tracker object.
We don't use the jobname to represent the mapping, because we need to support migration from just using jobs without renaming the existing jobs, to meet requirement 95.
It may not even be a good idea to create jobs with special names because it would look like we're using the name, and we're not. We don't want to confuse users or administrators or developers who won't read this paragraph. On the other hand, for people who use both systems, it would be useful to be able to see at a glance which issue a job corresponds to.
Associated filespecs are stored in a field in the job.
At installation time, the administrator must create a
P4DTI-filespecs field in the job to store the associated
filespecs; see section 4.1.
In Perforce, changed entities are identified using the p4
logger command, available in Perforce 2000.1. The logger must be
started by setting the logger counter to zero with p4
counter logger 0. It is a bad idea to do this more than once;
see [Seiwald
2000-09-11].
The output of p4 logger gives a list of changed
changelists and jobs that looks like this:
435 job job000034
436 change 1234
437 job job000016
Changes to the fixes relation show up in the logger output as changes to the associated changelist and job. Changes to the associated filespecs relation show up as changes to jobs.
We keep a counter (named p4dti- plus the replicator id)
that records the highest log entry we've dealt with. At the start of a
poll, we use p4 logger -t p4dti-rid to get fresh log
entries. At the end of a successful poll we update the counter to the
highest sequence number we read with p4 logger -c
sequence-number -t p4dti-rid. If the highest
sequence number we read is in fact the last entry in the log, this has
the side effect of clearing the log. See p4 help
undoc.
To avoid replicating changes made by the replicator back to the defect tracker, and so doubling the frequency of conflicts (see for example job000042), the replicator keeps track of how many times it has updated each job in the course of a poll, either through editing the job directly, or through creating, modifying, or deleting a fix. On the next poll the corresponding number of log entries can be discarded; then a job is replicated only if it has log entries remaining.
It is important to distinguish changes made by users of Perforce from changes replicated from the defect tracking system, so that these changes are not replicated back again (this would not necessarily be harmful, but it would double the likelihood of inconsistency, since there would be twice as many replications, and so possibly fail to meet requirement 1).
In Perforce 2002.1 or later, the P4DTI-user field in a
job gives the user who last updated that job (either through editing the
job directly or through issuing a fix against it).
In older versions of Perforce, there's no reliable way to determine who last modified a job; see job000016.
So the replicator makes its best guess at who last modified a job by using more information from Perforce, as follows:
Is there a fix record, submitted more recently than the job has been modified, by someone other than the replicator? If so, take the person who submitted the most recent such fix as the modifier.
If not, does the P4DTI-user field contain a user
other than the replicator? If so, take them as the
modifier.
If not, take some suitable user (the job owner, say) as the modifier.
This approach can be fooled by making a fix and then deleting it before the replicator polls.
Changes to changelists are replicated from Perforce to the defect tracking system only, so there is no need to make this distinction.
Note 1: If someone edits the same job twice in Perforce before the replicator can replicate it, then the replicator cannot determine what the intermediate state was. This has consequences when the defect tracker has a workflow model: suppose that a job status changes from A to B (which corresponds to transition T) and then from B to C (which corresponds to transition U). But the replicator sees only the status change from A to C, which doesn't correspond to any transition. So the workflow can't be consistently recorded in the defect tracker. There's nothing the replicator can do about this: the intermediate state of the job is not recorded in Perforce.
The integration does not support deletion of jobs and defect tracking issues. Deletion of jobs and issues is a bad idea anyway, since you lose information about the history of activity in the system.
Because of the possibility of deletion of fixes, the replicator fetches all fix records in both systems when replicating an issue; it computes the differences between the lists and replicates the additions, updates and deletions.
The replicator initiates the replication of unreplicated issues by applying a policy function, which is configurable by the administrator of the replication. We want to support organizations which have multiple Perforce servers (requirement 96). It may not be possible to tell which Perforce server an issue should be replicated to until some point in the workflow (perhaps when the issue is assigned to a project or to a developer). So each replicator should examine each unreplicated issue each time that issue changes, and apply the policy function to determine if the issue should be replicated.
Justification for this decision was given in [GDR 2000-10-04] and is repeated here:
There are three solutions to the problem of getting started with replication (that is, deciding which cases to replicate, and which Perforce server to replicate them to, when there are multiple Perforce servers):
The replicator identifier and Perforce server fields in the case is editable by the defect tracker user, who picks the appropriate Perforce server at some point.
The defect tracker picks a replicator and Perforce server at some point, by applying a policy function configured by the administrator of the integration.
Each replicator identifies cases that are not yet set up for replication and decides whether it should replicate them, by applying a policy function configured by the administrator of the integration.
Solution 1 is the least appropriate. The defect tracker user may not have the knowledge to make the correct choice. The point of the integration is to make things easier for users, and selection of Perforce server should be automated if possible. By exposing the Perforce server field to the user, we run into other difficulties: should the field be editable? What if the user makes a mistake? Best to avoid these complexities.
2 and 3 are similar solutions, but 3 keeps the integration configuration in one place (in the replicator) where it is easier to manage than if it is split between the replicator and defect tracker. It is also the solution that depends least on support from the defect tracking vendor.
The replicator has no internal state. Each database has its own record of how its entities relate to entities in the other database, and what the replicator has replicated. These records are updated only when they are known to be consistent with the other system. This makes it possible to check the consistency of the whole system using a separate tool, increasing our confidence in the correctness of the replication algorithm. It also means that replicator is robust against problems occurring in the middle of a replication (such as the network going down, or the replicator's machine crashing, or the replicator running out of memory): if it can't complete a replication, then as far as it is concerned, it hasn't yet done it. So the next time it runs, it will try the replication again.
This design principle helps to meet requirement 1.
See [NB
2000-11-24] for the design decision that matches the steps in this
algorithm to method calls in the defect_tracker class [RB 2000-10-16, 7.1].
Get the set of changed jobs in Perforce and the set of new and changed issues in the defect tracking system. The latter involves looking for new, changed and deleted filespec and fix records as well, and getting the issue with which the record is associated.
For each corresponding pair (job, issue):
Decide whether to replicate from Perforce to the defect tracker; replicate from the defect tracker to Perforce; or do nothing, as follows:
If the job has changed but not the issue, replicate from Perforce to the defect tracker.
If the issue has changed but not the job, replicate from the defect tracker to Perforce.
If neither the job nor the issue has changed, do nothing.
If both have changed, apply a policy function to decide what to do. The administrator might set up a rule here that says, "Perforce is always right" or "the defect tracker is always right", or something more complex. The default rule is to overwrite the job with the issue.
To replicate from Perforce to the defect tracker:
Get all the fixes and filespecs for the job and the issue
(the filespecs for the job are in the P4DTI-filespecs
field in the job; see section-4.1).
If the defect tracker supports workflow transitions, choose an appropriate transition [GDR 2000-11-17]:
Has the job status changed? If not, the transition is some default "update" transition, as specified in the defect tracking object's configuration.
Otherwise, apply some function to all the data to work out what workflow transition to apply. This will typically be a function of the old state and the new state.
This function may not always be able to get it right, since it may not be able to work out the intention of the user who edited the job in Perforce, or the edits they made may not correspond to a transition, or multiple changes have happened in Perforce before the replicator noticed, and the sum of these changes doesn't correspond to any valid transition; see section 2.6.
Apply the transition to the issue in the defect tracker so that it matches the job in Perforce. If the defect tracker has no transitions, just update the issue.
If the transition or update succeeded, update the fixes and filespecs in the defect tracker (if necessary) to match those in Perforce.
To replicate from the defect tracker to Perforce:
Get all the fixes and filespecs for the job and the issue.
Update the fixes in Perforce so that they match the fixes in the defect tracker.
Update the job in Perforce so that it matches the issue and its associated filespecs.
The replicator requires the fields below to be present in the Perforce jobspec. The field numbers for these added fields are not important. They are presented here for illustration only.
Fields: 191 P4DTI-filespecs text 0 optional
The P4DTI-filespecs field contains a list of filespecs
that are associated with the job, one per line.
Fields: 192 P4DTI-issue-id word 0 required
Preset-P4DTI-issue-id: None
The P4DTI-issue-id field contains a string from which
the defect tracker object can deduce the identifier of the corresponding
issue, or None if the job is not replicated.
Fields: 193 P4DTI-rid word 32 required
Preset-P4DTI-rid: None
The P4DTI-rid field contains the identifier of the
replicator that replicates this job, or None if the if job is not
replicated.
Fields: 194 P4DTI-user word 32 always
Preset-P4DTI-user: $user
The P4DTI-user field is the Perforce user who last
modified the job.
See [RB 2000-11-20a], [RB 2000-11-20b], [RB 2000-11-20c], [RB 2000-11-28a], [RB 2000-11-28b] for the original design decisions for the P4DTI configuration.
Each user function of the P4DTI corresponds to a Python script. There are three of these:
check.py |
Check that the defect tracker database and the Perforce jobs system are consistent and produce a report stating any inconsistencies. |
refresh.py |
Delete all Perforce jobs and then replicate all issues modified since the start date from the defect tracking system to Perforce [RB 2000-11-29]. |
run.py |
Start the replicator. |
Each of these scripts has the same basic pattern: it imports the
object r (the replicator object) from the
init.py module, and calls a method of that
object. For example, here's the complete executable contents of the
run.py script:
from init import r
r.run()
The init.py module has three
functions:
To construct an object dt to
represent the defect tracker;
To construct an object r to
represent the replicator; and
To set up the Perforce jobspec so that issues can be replicated.
Figure 2 shows the dataflow during configuration of the P4DTI.
Figure 2. Dataflow during configuration
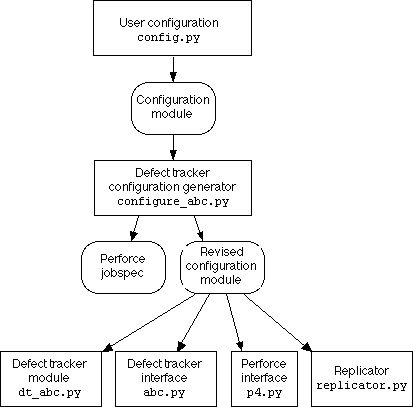
This is what happens during initialization:
The configuration comes initially from the user settings in
config.py module. This module is
accessed by importing config_loader.py, which contains code to
check the P4DTI_CONFIG environment variable.
from config_loader import config
The dt_name configuration parameter
names a defect tracker. This name, converted to lowercase, is used
to import the configuration generator for that defect tracker, which
must be called configure_defect_tracker.py, and the
defect tracker module.
dt_name = string.lower(config.dt_name)
configuration_module = __import__('configure_' + dt_name)
dt_module = __import__('dt_' + dt_name)
The config module is passed to the
configuration function in the configuration generator
module, which returns a Perforce jobspec and a revised configuration
module.
jobspec, config = configure_module.configuration(config)
The revised configuration is passed to the defect tracker
constructor to build the dt object representing the
defect tracker.
dt = dt_module.__dict__['dt_' + dt_name](config)
The revised configuration is used to build a Perforce interface.
p4_interface = p4.p4(
client = ('p4dti-%s' % socket.gethostname()),
client_executable = config.p4_client_executable,
password = config.p4_password,
port = config.p4_port,
user = config.p4_user,
logger = config.logger)
The Perforce jobspec is updated.
p4_interface.run('jobspec -i', jobspec)
The revised configuration is passed to the replicator
constructor to build the object r representing the
replicator. The replicator is initialized (this also initializes
the defect tracker by calling its init() method).
r = replicator.replicator(dt, p4_interface, config)
r.init()
The replicator object is now ready for whatever action is next requested (checking consistency, refreshing Perforce jobs, or starting the replicator).
| [GDR 2000-09-07] | "Replicator design notes 2000-09-07" (e-mail message); Gareth Rees; Ravenbrook Limited; 2000-09-08 15:59:19 GMT. |
| [GDR 2000-10-04] | "Design decision: starting replication" (e-mail message); Gareth Rees; Ravenbrook Limited; 2000-10-04 16:31:12 GMT. |
| [GDR 2000-11-17] | "Re: TeamShare/Perforce integration planning meeting, 2000-08-16" (e-mail message); Gareth Rees; Ravenbrook Limited; 2000-11-17 17:00:25 GMT. |
| [NB 2000-11-24] | "Defect tracker design discussion" (e-mail messages); Nick Barnes; Ravenbrook Limited; 2000-11-24. |
| [RB 2000-08-10] | "Replication mapping design notes" (e-mail message); Richard Brooksby; Ravenbrook Limited; 2000-08-10 11:27:03 GMT. |
| [RB 2000-08-30] | "Design document structure" (e-mail message); Richard Brooksby; Ravenbrook Limited; 2000-08-30. |
| [RB 2000-10-05] | "P4DTI Project Design Document Procedure"; Richard Brooksby; Ravenbrook Limited; 2000-10-05. |
| [RB 2000-10-16] | "Perforce Defect Tracking Integration Integrator's Guide"; Richard Brooksby; Ravenbrook Limited; 2000-10-16. |
| [RB 2000-11-08] | "Replicator architecture design discussion, 2000-11-01/02"; Richard Brooksby; Ravenbrook Limited; 2000-11-08. |
| [RB 2000-11-20a] | "Automatic configuration design" (e-mail message); Richard Brooksby; Ravenbrook Limited; 2000-11-20. |
| [RB 2000-11-20b] | "Re: Automatic configuration design" (e-mail message); Richard Brooksby; Ravenbrook Limited; 2000-11-20. |
| [RB 2000-11-20c] | "Re: Automatic configuration design" (e-mail message); Richard Brooksby; Ravenbrook Limited; 2000-11-20. |
| [RB 2000-11-28a] | "Case of state names" (e-mail message); Richard Brooksby; Ravenbrook Limited; 2000-11-28. |
| [RB 2000-11-28b] | "Distinguished state to map to 'closed'" (e-mail message); Richard Brooksby; Ravenbrook Limited; 2000-11-28. |
| [RB 2000-11-28c] | "Abolishing the role of resolver" (e-mail message); Richard Brooksby; Ravenbrook Limited; 2000-11-28. |
| [RB 2000-11-29] | "Setting items to be replicated" (e-mail message); Richard Brooksby; Ravenbrook Limited; 2000-11-29. |
| [Seiwald 2000-09-11] | "Re: Is 'p4 counter logger 0' idempotent?" (e-mail message); Christopher Seiwald; Perforce Software; 2000-09-11 16:45:04 GMT. |
| 2000-09-13 | GDR | Created based on [RB 2000-08-10], [RB 2000-08-18], [RB 2000-08-30] and [GDR 2000-09-07]. |
| 2000-09-14 | GDR | Improved definition of P4DTI-filespecs and
P4DTI-status fields. |
| 2000-09-17 | GDR | Added some references to requirements. |
| 2000-10-04 | GDR | Added design decision from [GDR 2000-10-04]. |
| 2000-10-10 | GDR | Made changes identified in review on 2000-10-09. |
| 2000-10-15 | GDR | Applied design decision on conflict resolution [GDR 2000-10-05]. |
| 2000-12-01 | RB | Updated references to the "SAG" to "AG" since it's now called the Administrator's Guide. |
| 2001-03-02 | RB | Transferred copyright to Perforce under their license. |
| 2001-03-13 | GDR | Deleted the recording of conflicts and the need for manual conflict resolution. Conflict resolution is always immediate [RB 2000-11-28c]. |
| 2001-03-21 | GDR | Added configuration architecture and design. |
| 2001-03-22 | GDR | Added design principle: no internal state. |
| 2002-01-28 | GDR | Improved design for determining changed entities and job modifier to take advantage of Perforce 2002.1 accurately recording who last modified a job. |
This document is copyright © 2001 Perforce Software, Inc. All rights reserved.
Redistribution and use of this document in any form, with or without modification, is permitted provided that redistributions of this document retain the above copyright notice, this condition and the following disclaimer.
This document is provided by the copyright holders and contributors "as is" and any express or implied warranties, including, but not limited to, the implied warranties of merchantability and fitness for a particular purpose are disclaimed. In no event shall the copyright holders and contributors be liable for any direct, indirect, incidental, special, exemplary, or consequential damages (including, but not limited to, procurement of substitute goods or services; loss of use, data, or profits; or business interruption) however caused and on any theory of liability, whether in contract, strict liability, or tort (including negligence or otherwise) arising in any way out of the use of this document, even if advised of the possibility of such damage.
$Id: //info.ravenbrook.com/project/p4dti/branch/2005-03-02/agena-extension/design/replicator/index.html#1 $
Ravenbrook / Projects / Perforce Defect Tracking Integration / Master Product Sources / Design